
Основой удачного продвижения сайта в поисковых системах либо пуска контекстной рекламы постоянно являлось верно собранное семантическое ядро. В данной статье показан весь процесс сбора и сортировки запросов.
Мы разделили работу на три главных шага:
- Сбор разновидностей написания продукта и маркеров.
- Сбор и чистка семантического ядра в Key Collector.
- Кластеризация (сортировка) семантического ядра.
Каждый шаг мы разберем на образце группы продуктов «Шлемы для мотоцикла», для которой и соберем семантическое ядро.
Чтение статьи займет у вас чуток больше 10 минут. Но ежели вы не чрезвычайно любите читать, то сможете истратить приблизительно то же время на просмотр ролика.
Шаг 1. Сбор разновидностей написания продукта и маркеров
Перед сбором запросов необходимо выявить все вероятные варианты написания продвигаемого продукта, также маркеры (характеристики) . Для этого мы используем сервис подбора слов Яндекса.
Методика
- Вписываем заглавие нашего продукта в поисковую строчку и давим клавишу «Подобрать».
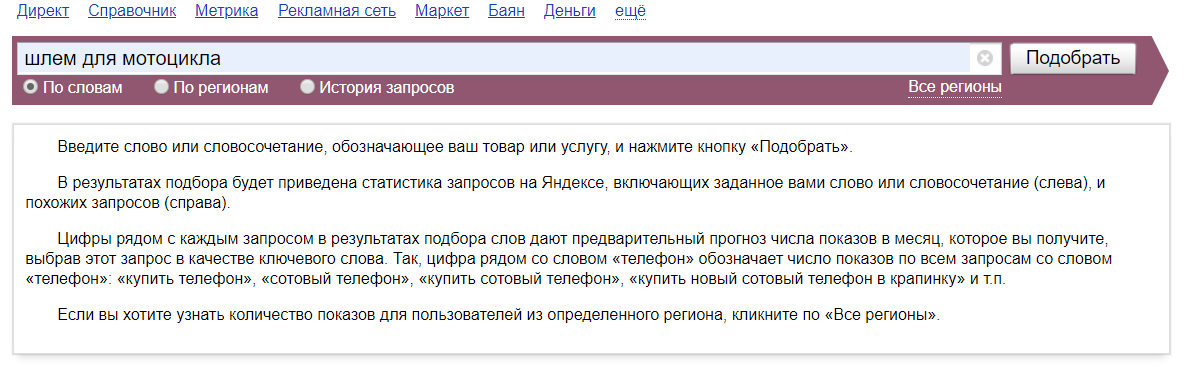
- Детально просматриваем запросы из правой колонки приобретенных результатов и выявляем синонимы либо другие варианты нашего запроса.
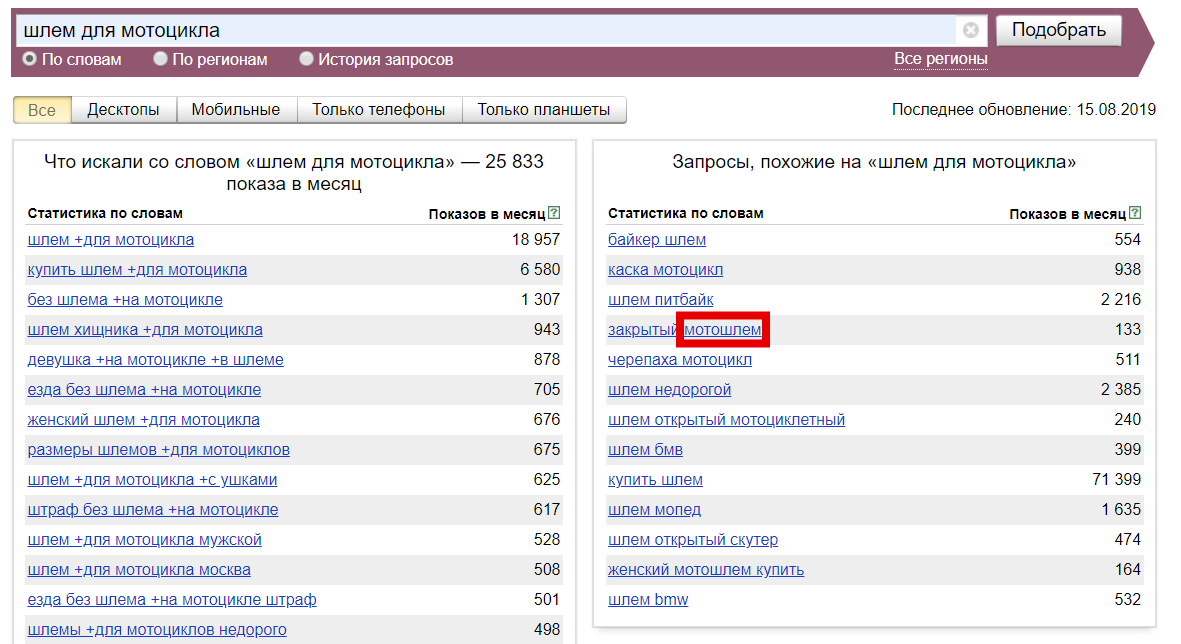
- Переносим все отысканные варианты наименования продукта в отдельный файл.

- На последующем шаге идет смонтировать маркеры, другими словами характеристики, определяющие продукт. Данные маркеры можнож объединить по типам похожих параметров, к примеру, Цвет, Бренд, Тип и других.
Для выявления маркеров есть два пути:
1.Сбор и следующая чистка всей семантики по наименованию продукта, к примеру, «Мотошлем».
1.1. Плюс: Сбор всех имеющихся в спросе маркеров;
1.2. Минус: Длинный и трудоемкий процесс.
2. Поиск и анализ страничек соперников в ТОП 10, которые теснее имеют странички с нашим продуктом.
2.1. Плюс: Прыткий процесс;
2.2. Минус: Неполный сбор параметров, ежели они отсутствуют у соперников.
- Используя 2-ой вариант, обретаем сайты соперников по запросам наименования продукта, брав странички из ТОП 10. Это вероятно сделать вводом главного запроса прямо в поисковую систему либо же воспользоваться прибором настоящего поиска соперников по видимости их страничек, как было поведано в 4 пт первого шага данной статьи.
- На страничке соперника, необходимо направить внимание на структуру категории, другими словами есть ли подкатегории, либо поглядеть функционал фильтрации продуктов. В нем теснее находятся группы параметров, снутри которых мы можем узреть маркеры.
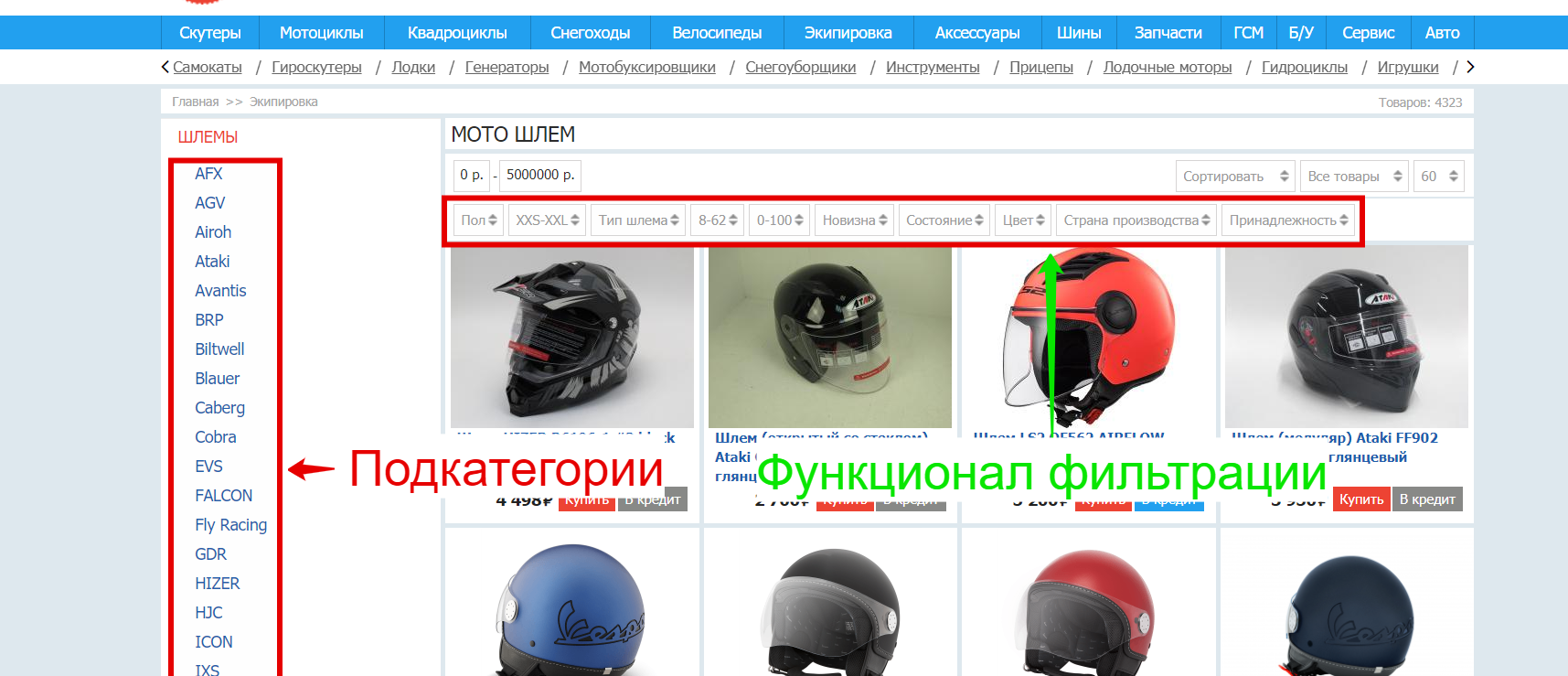
- Копируем подкатегории и/или маркеры, которые нас интересуют, другими словами то, что вправду есть у продвигаемого сайта в ассортименте, и выносим в наш файл:
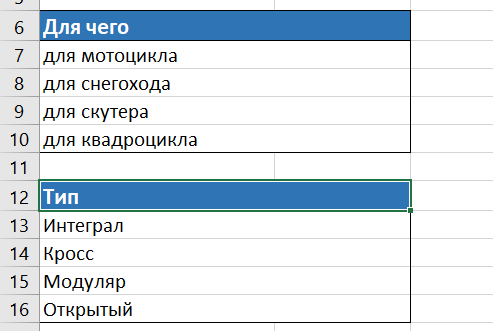
- Последующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтоб получить разные запросы для последующего сбора семантического ядра теснее по ним. Рекомендуем применять функцию «СЦЕПИТЬ» в Microsoft Excel. В итоге получим таблицу, подобную представленной ниже:
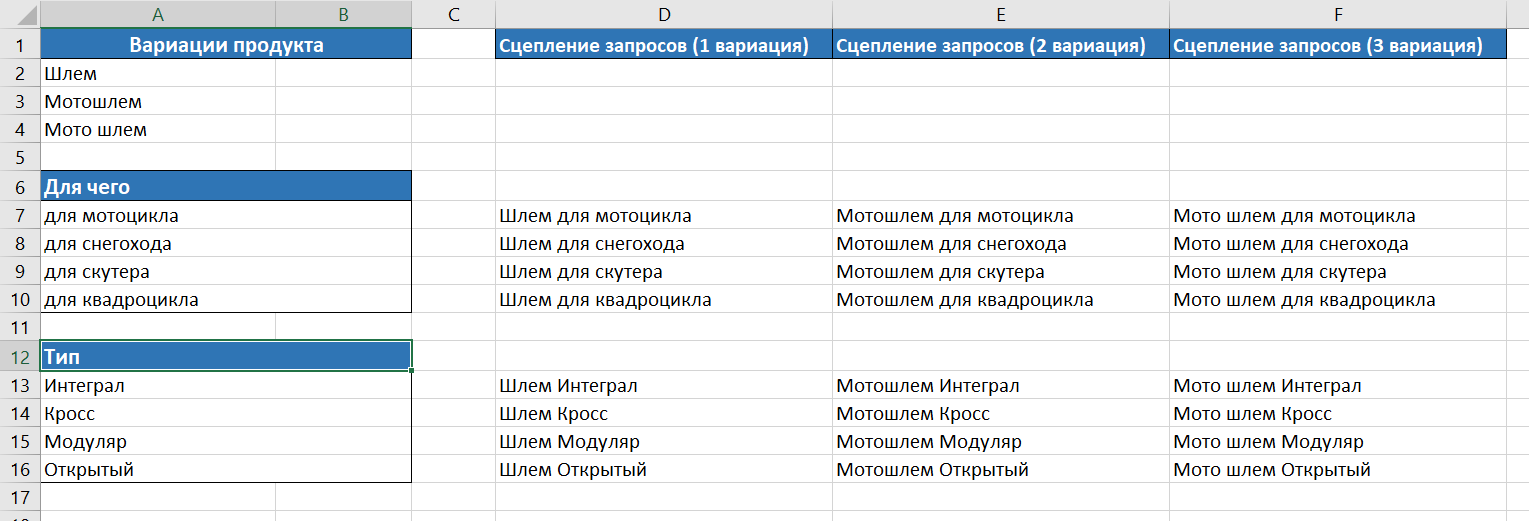
- Для пакетной (разовой) загрузки всех ключевиков в KeyCollector идет вновь воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ») . Таковым образом мы сможем разом добавить все запросы в единичное поле программы, которая в свою очередь создаст нужные группы и добавит в их подходящие запросы для расширения ядра. Итоговый перечень запросов в нужном формате:
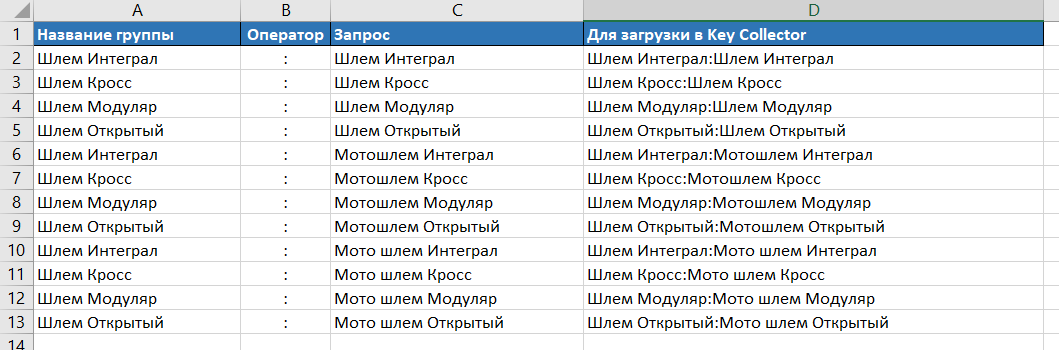
Шаг 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому идет собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, другими словами ежели ваш магазин находится в Москве, то и запросы с их частотностью необходимо собирать по данному региону. Для этого в нижней доли окна мы избираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

Опосля выбора региона можнож приступать к сбору семантики.
Методика
- В главном меню давим клавишу «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

- В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. Опосля их прибавления в нижней правой доли окна идет надавить на иконку разделения фраз по группам:
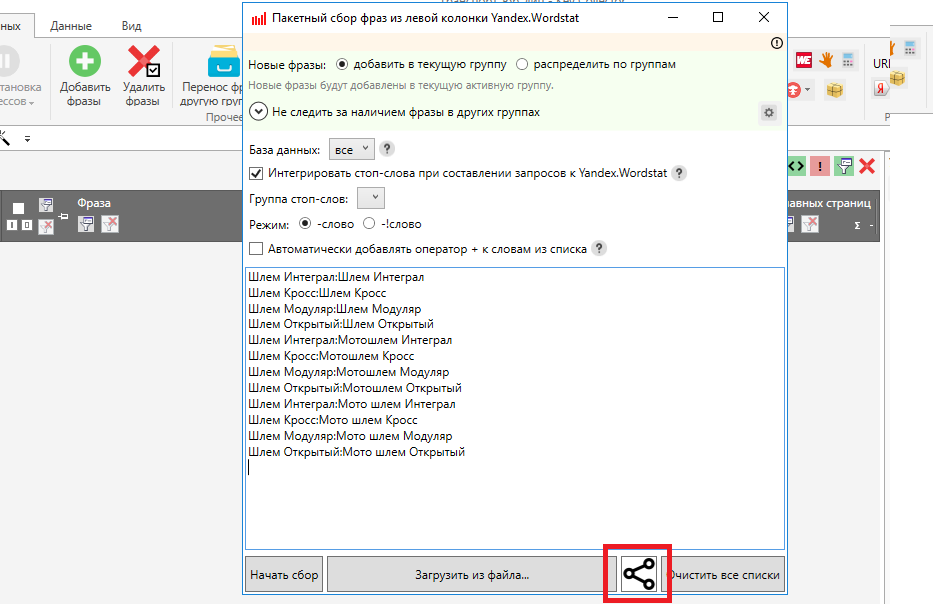
- Опосля нажатия на клавишу в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне возникло поле с наименованиями наших групп, снутри которых находятся подходящие запросы. Дальше мы можем давить клавишу «Начать сбор»:
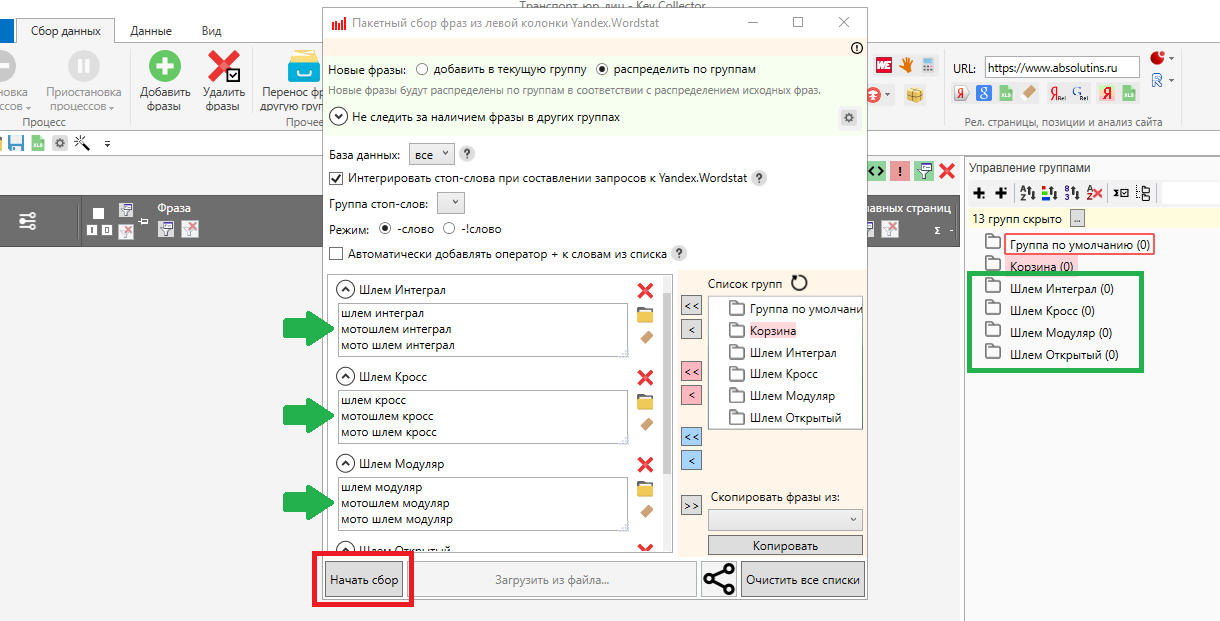
Запустив парсинг левой колонки Yandex.Wordstat, мы автоматом получаем все расширения наших запросов из сервиса, и сейчас не будем собирать их вручную.
- Последующим шагом является сбор корректной частоты запросов. Для этого идет очистить данные общей частотности, собранной совместно с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой клавишей мыши и выбрав пункт «Очистить данные в колонке»:
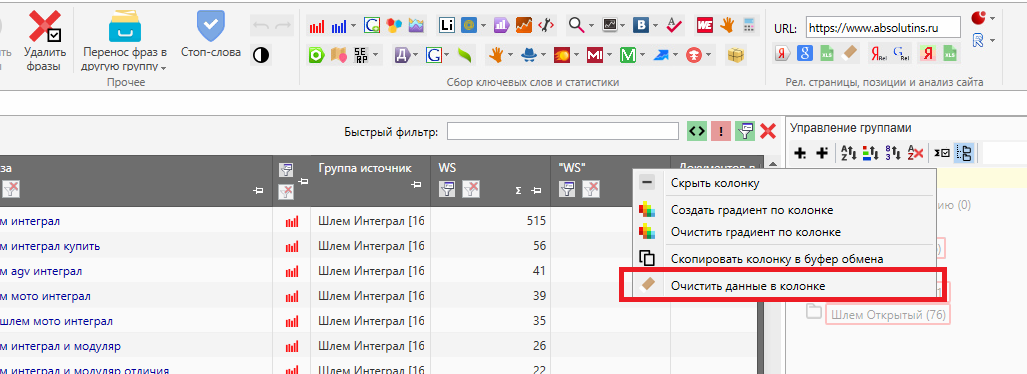
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

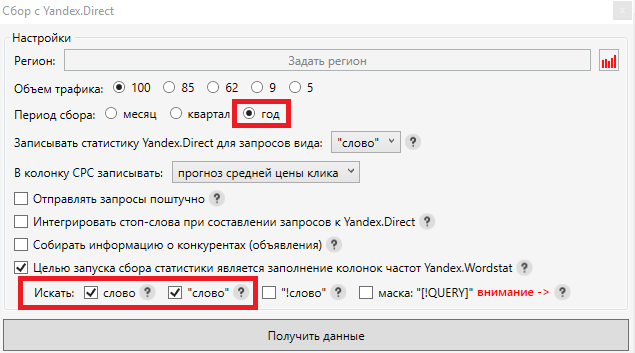
- Во всплывающем окне избираем период сбора одинаковый году. Это необходимо поэтому, что спрос на продукты нередко является сезонным, и без годовой частотности мы не сможем выявить самые знаменитые запросы. Целью сбора избираем «Базовую» и «Уточненную» частотность, опосля чего же давим клавишу «Получить данные»:
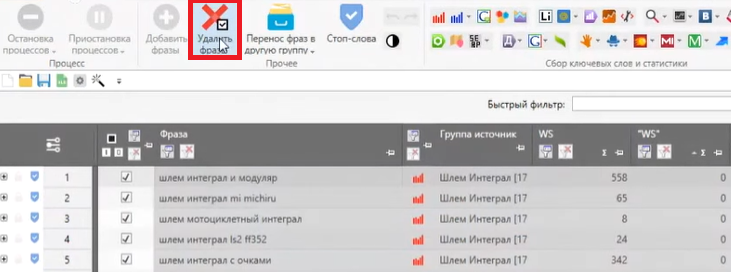
- Когда частотность собралась, можнож переходить к чистке семантики от мусорных фраз. Мы рекомендуем устранять запросы с «Уточненной» частотностью наименее 10, потому что это значит, что сходственные запросы приносят меньше 1 гостя за месяц.
Выделяем такие запросы и давим клавишу «Удалить фразы»:
- Сейчас можнож приступить к чистке запросов по фразам.
Для этого есть несколько приборов:
1. Инструмент фильтрации дозволяет живо отсечь часть негодных запросов. Используя его, можнож бросить в главной таблице лишь те фразы, которые включают в себя английские знаки, числа либо состоят из 4 и наиболее слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление либо следующий перенос в другую/новую группу по заблаговременно загруженным в поле словам. Можнож сходу выделить запросы с вхождениями городов (хороших от выбранного региона) , заглавий компаний соперников, также информационные запросы со словами «как», «почему», «отзывы», «реферат» и прочие.
3. Инструмент «Анализ групп» позволяет смонтировать запросы в группы по разным вариантам сортировки и отмечать наименования групп, выделяя сходу несколько запросов для удаления либо последующего переноса в другую/новую группу.
- Рекомендуем воспользоваться всеми приборами, главным из которых обязан стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можнож узреть несколько вариантов сортировки, из которых мы рекомендуем применять способ «по отдельным словам».
В данном способе все запросы будут находиться в таблице не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется отыскивать позднее вручную в общем перечне запросов.
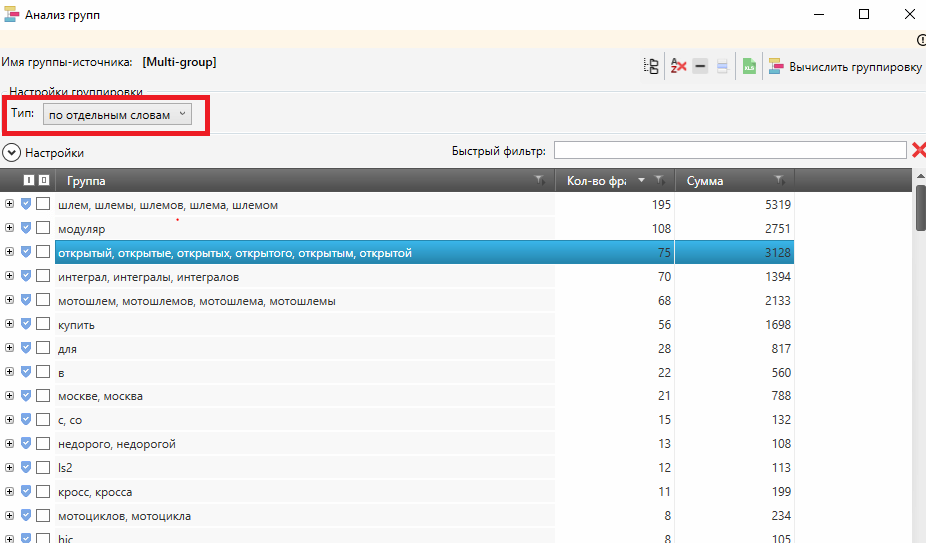
- Просматривая группы одну за иной, отмечаем их либо фразы снутри их, которые очевидно нам не подходят. В процессе мы будем следить, что, избирая 5 групп, мы теснее отметили в общей таблице 9 фраз:
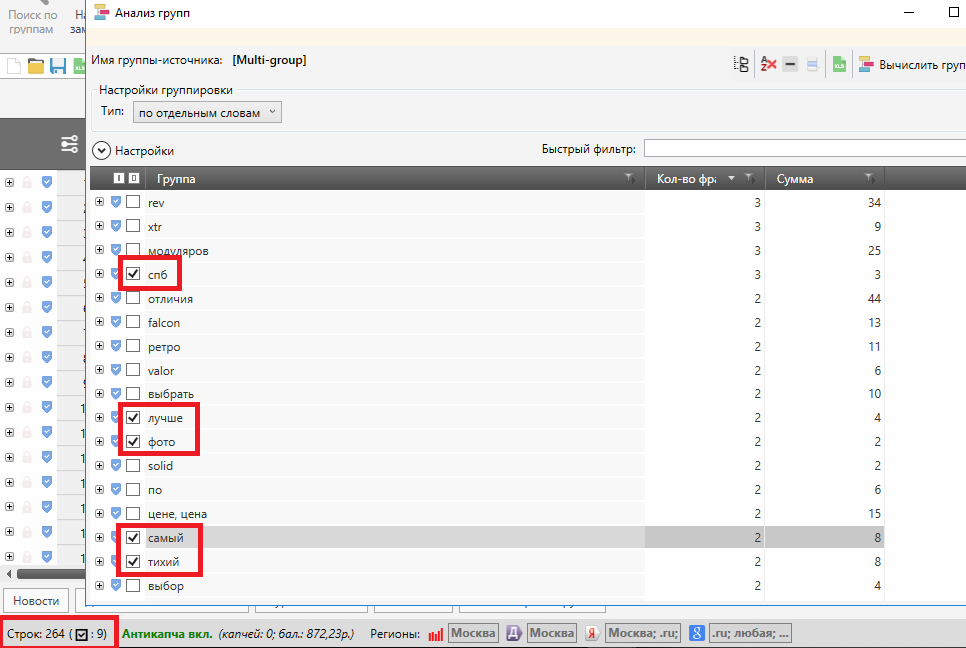
- Опосля того как отметим все группы и запросы в их, мы можем закрыть данное окно и надавить на клавишу «Удалить фразы».
Опосля чего же идет перейти к выгрузке запросов в Excel для следующей ручной чистки запросов и сортировки семантики.
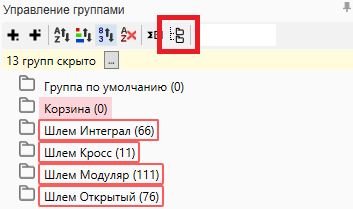
- Чтоб совершить пакетную выгрузку всех запросов из различных групп, необходимо в правой колонке программы отметить все наши группы и надавить клавишу «Режим просмотра мульти-группы». Опосля этого можнож выгрузить наше семантическое ядро в Microsoft Excel:
Шаг 3. Кластеризация (сортировка) семантического ядра
Приобретенный перечень запросов нам необходимо разбить на кластеры для следующей проработки посадочных страничек. Чтоб корректно выполнить эту задачку, необходимо применять сервисы кластеризации запросов, работающие на базе выдачи поисковых систем. Конкретно таковой формат анализа, способности продвижения тех либо других запросов на одной либо различных страничках дает 70% фуррора при последующем продвижении сайта.
Знаменитые программные продукты:
1. KeyAssort – программа для кластеризации и структуризации семантического ядра.
2. Key Collector – функционал «Анализ групп» с типом сортировки «По поисковой выдаче») .
Знаменитые онлайн-сервисы:
Осмотрим методику сортировки запросов с поддержкою сервиса Engine Seointellect.
Методика
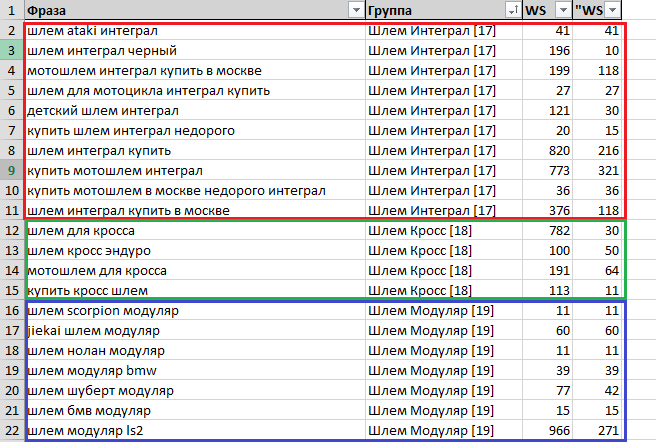
- Приобретенный перечень запросов, который мы выгрузили из программы Key Collector, содержит столбец с заглавием «Группа». Нам необходимо по очереди прибавлять все запросы из каждой группы в кластеризатор.
- Заходим в сервис и избираем в меню слева пункт «Кластеризация запросов». В открывшемся блоке мы видим клавишу «Новенькая группировка».
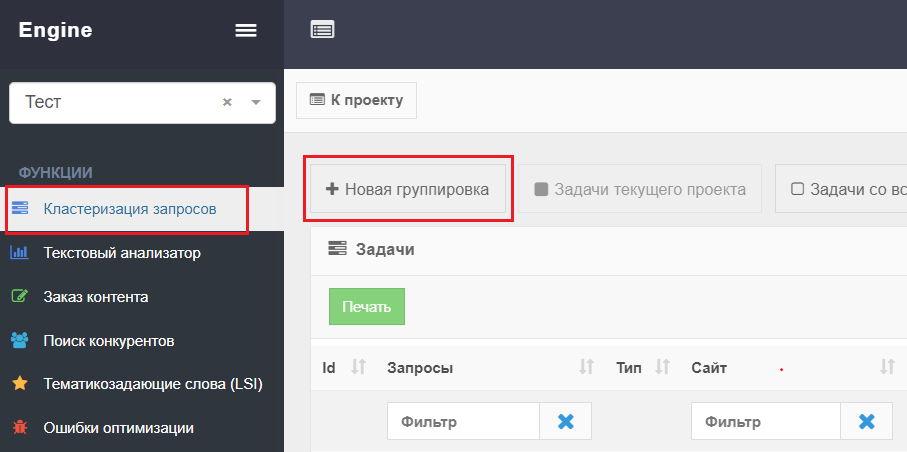
- Давим на данную клавишу. На экране покажутся последующие поля для наполнения:
1. Добавить запросы – в данный блок мы прибавляем все запросы из первой анализируемой группы.
2. Вид группировки включает в себя три вида жесткости кластеризации:
2.1.«Hard» – твердая сортировка.
2.2.«Balance» – сортировка средней жесткости.
2.3.«Soft» – сортировка низкой жесткости.
Подробнее про различие работы способов сортировки можнож поглядеть в данном видео:
При сортировке коммерческих запросов, как в нашем случае, идет вначале избирать способ сортировки «Hard», ежели запросы информационные, то рекомендуем воспользоваться лишь способом «Soft».
3. Регион избираем подходящий регион продвижения.
4. Мой сайт не необходимо указывать, потому что эта функция нужна для определения запросов по теснее имеющимся посадочным страничкам указанного сайта.
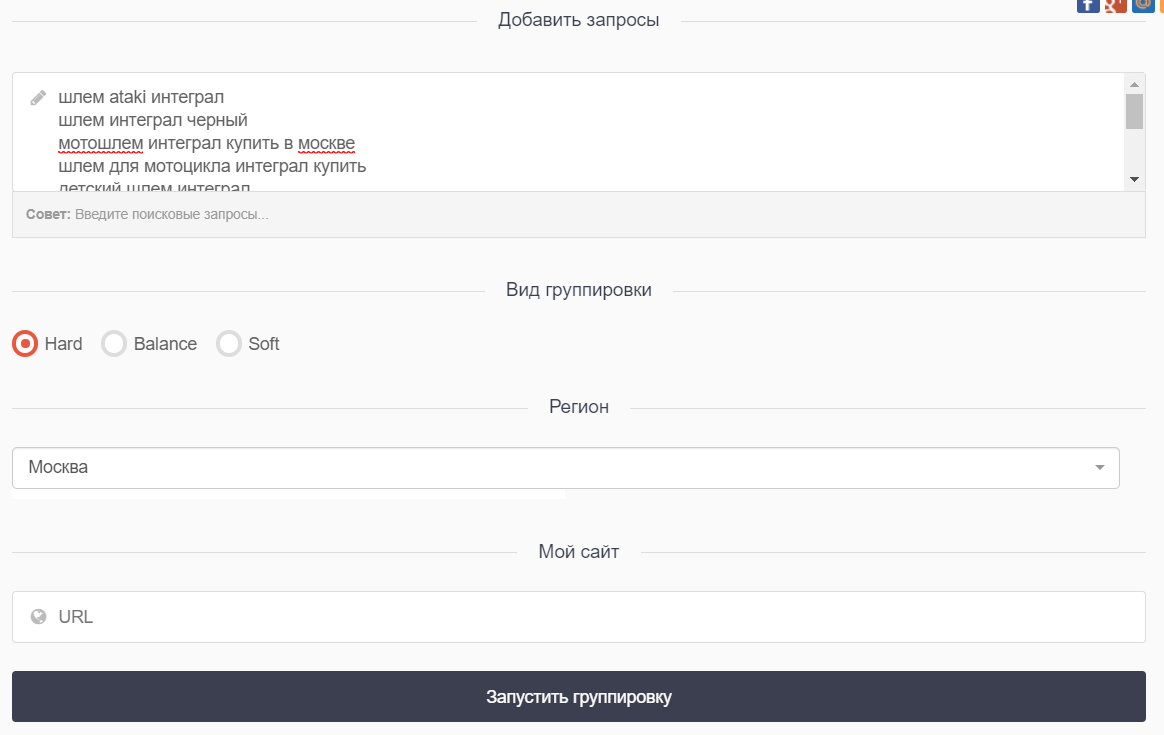
- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа в правой доли сделанного задания заместо отображения процесса покажется иконка «Глаз», на которую необходимо надавить.
- Мы попадаем на страничку результата сортировки и можем проанализировать данные:
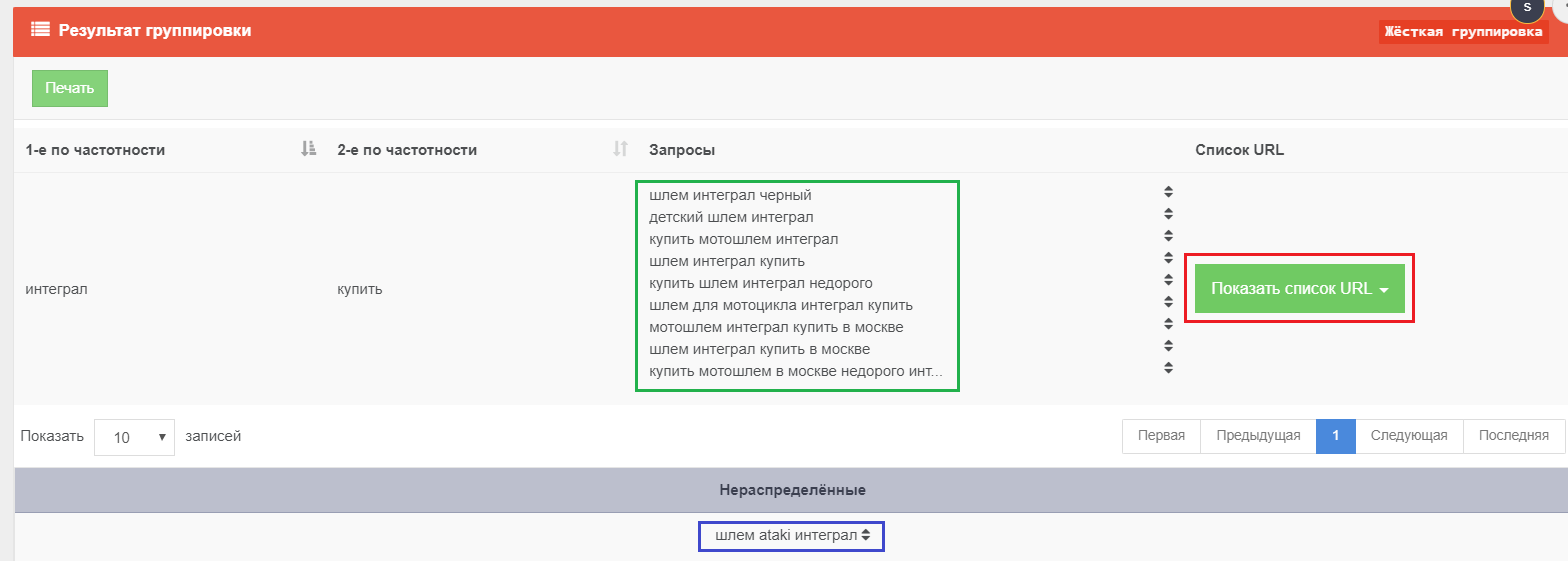
1. Мы видим, что все наши запросы, не считая 1-го, попали в одну группу (отмечено зеленоватым) , а значит их можнож продвигать совместно на одной посадочной страничке.
2. Также находится нераспределенный запрос (отмечено голубым) , это значит, что по данному запросу результаты выдачи сильно различаются от результатов других запросов. В таком случае идет сделать вывод, что под этот запрос необходимо творить отдельную посадочную страничку бренда Ataki.
3. Справа от группы есть функционал «Показать перечень URL», нажав на который раскроется блок со ссылками на странички из ТОП 10, по которым была проведена кластеризация.
- Ежели бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можнож продвигать в готовых группах. Можнож просто узреть эти запросы и перенести в подходящую группу, но ежели фраз много, то их идет выслать на сортировку по способу «Soft». Приобретенные группы по способу сортировки «Soft» соединить с группами, приобретенными ранее по способу «Hard».
- Проведя данные события с каждой группой из нашего файла, мы получим готовый перечень разделенных запросов, для следующей проработки страничек.
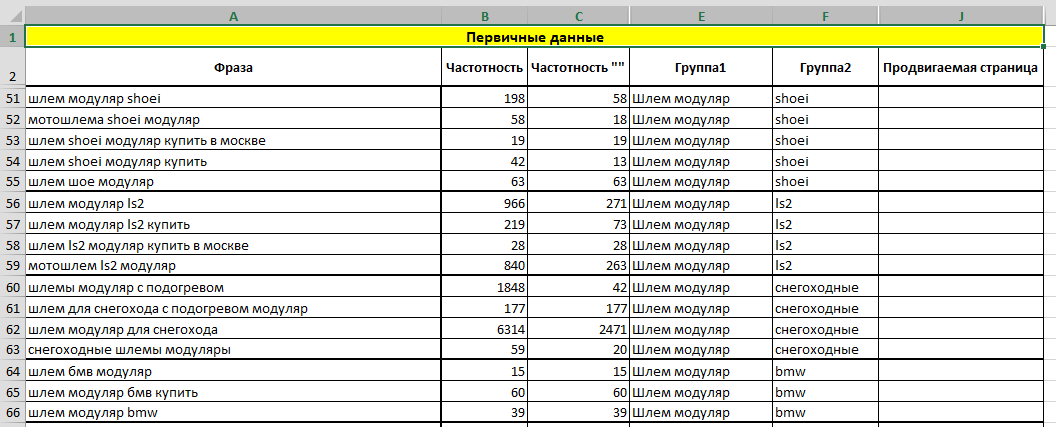
Финальная версия файла семантического ядра
Итоговый файл с семантическим ядром обязан представлять собой таблицу, включающую последующие столбцы с данными:
1. Запрос
2. Группа
3. Базисная частотность
4. Уточненная частотность
5. Посадочная страница
Все группы мы рекомендуем отделять чертой друг от друга, чтоб потом с таковым файлом было легче работать:
Выводы
Сейчас вы понимаете, как трудоемким является процесс сбора и сортировки семантического ядра для продвижения сайта либо опции контекстной рекламы.
Это лишь базисная аннотация, которая не обхватывает почти всех аспектов, возникающих в процессе, но конкретно эта работа является основой удачного заслуги целей продвижения, а значит исполнять ее некачественно равносильно бездействию, потому что вы не добьетесь никаких результатов без «построенного фундамента».
Комментариев: 0