
При анализе сайта на предмет технических ошибок мы нередко сталкиваемся с таковой неувязкой, как дубликаты страничек. Давайте подробнее разберемся, что это такое, какие виды дубликатов есть, как их выявить и избавиться.
Примечание: ежели вы понимаете что такое дубли страничек и чем они вредоносны для продвижения, можнож сходу перейти в 4-ый раздел «Как выявить дубли страниц».
Разберем общее понятие:
Дубликаты страниц — это полная или частичная копия главной веб-страницы на сайте, которая участвует в продвижении. Традиционно копия находится на отдельном URL-адресе.
Чем вредоносны дубликаты страничек при продвижении сайта?
Практически все обладатели страничек даже не подозревают о том, что на сайте может находиться великое количество дубликатов, наличие которых плохо сказывается на общем ранжировании сайта. Поисковые системы воспринимают данные документы как отдельные, потому контент странички перестает быть неповторимым, тем самым снижается ссылочный вес странички.
Наличие маленького количества дублей страничек не будет являться великий неувязкой для сайта. Но ежели их число зашкаливает, то от их необходимо избавляться в срочном порядке.
Виды дубликатов страниц
Есть разные виды дубликатов страничек, самые распространенные из их представлены в рисунке 1:
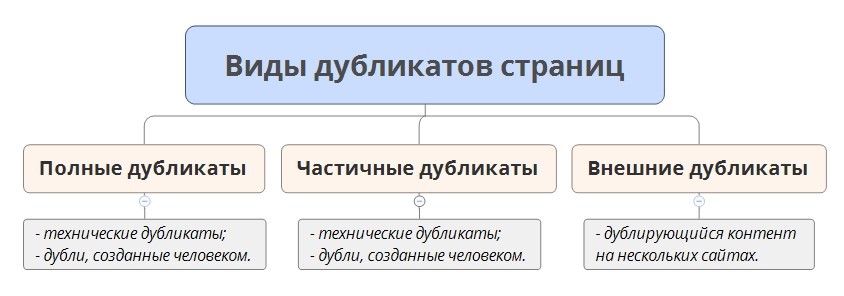
Рис. 1. Виды дубликатов страниц
Разберем подробнее выставленные виды дублей страничек.
Полные дубликаты страниц — полное дублирование контента веб-документа, различия лишь в URL-адресе.
Частичные дубликаты страниц — частичное дублирование контента веб-документов, когда дублируется заполнение сайта с маленькими различиями. К образцу, великие фрагменты текстов дублируются на нескольких страничках сайта — это теснее частичные дубликаты или схожие карточки продуктов, которые различаются лишь одной незначимой чертой.
Наружные дубликаты страничек — полное или частичное дублирование контента на различных сайтах.
Технические дубликаты — это дубликаты, которые генерируются автоматом из-за ошибочных опций системы управления сайтом.
Дубликаты, сделанные человеком — это дубликаты страничек, которые были сделаны по невнимательности самим вебмастером.
Как выявить дубли страничек?
Способов найти дубликаты страничек — множество. В данной статье осмотрим несколько главных способов, которые употребляются в работе почаще всего.
1. Парсинг сайта в сервисе
При парсинге сайта в каком-либо сервисе(в заключительнее время почаще всего употребляют сервис Screaming Frog)наглядно можнож узреть страницы-дубликаты.
К образцу, когда не склеены зеркала или у страничек есть какие-то свойства, которые добавляются автоматом при отслеживании эффективности маркетинговых кампаний и другие.

Рис. 2. Пример парсинга сайта в сервисе Screaming Frog при не склеенных зеркалах
Маленький лайфхак для работы с обслуживанием Screaming Frog: ежели у сайта громадное количеством страничек, и вы сходу увидели, что зеркала не склеены и поставили чертеж на парсинг, природно процесс замедлится и уменьшит скорость работы вашей системы(ежели у вашего ПК, окончательно, не сильные системные свойства).
Чтоб этого недопустить можнож применять функцию Configuration – URL Rewriting – Regex Replace.
В вкладке Regex Replace создаем последующее верховодило(используя постоянное выражение, «говорим» сервису, как необходимо склеивать зеркала, чтоб он выводил лишь странички с HTTPS):
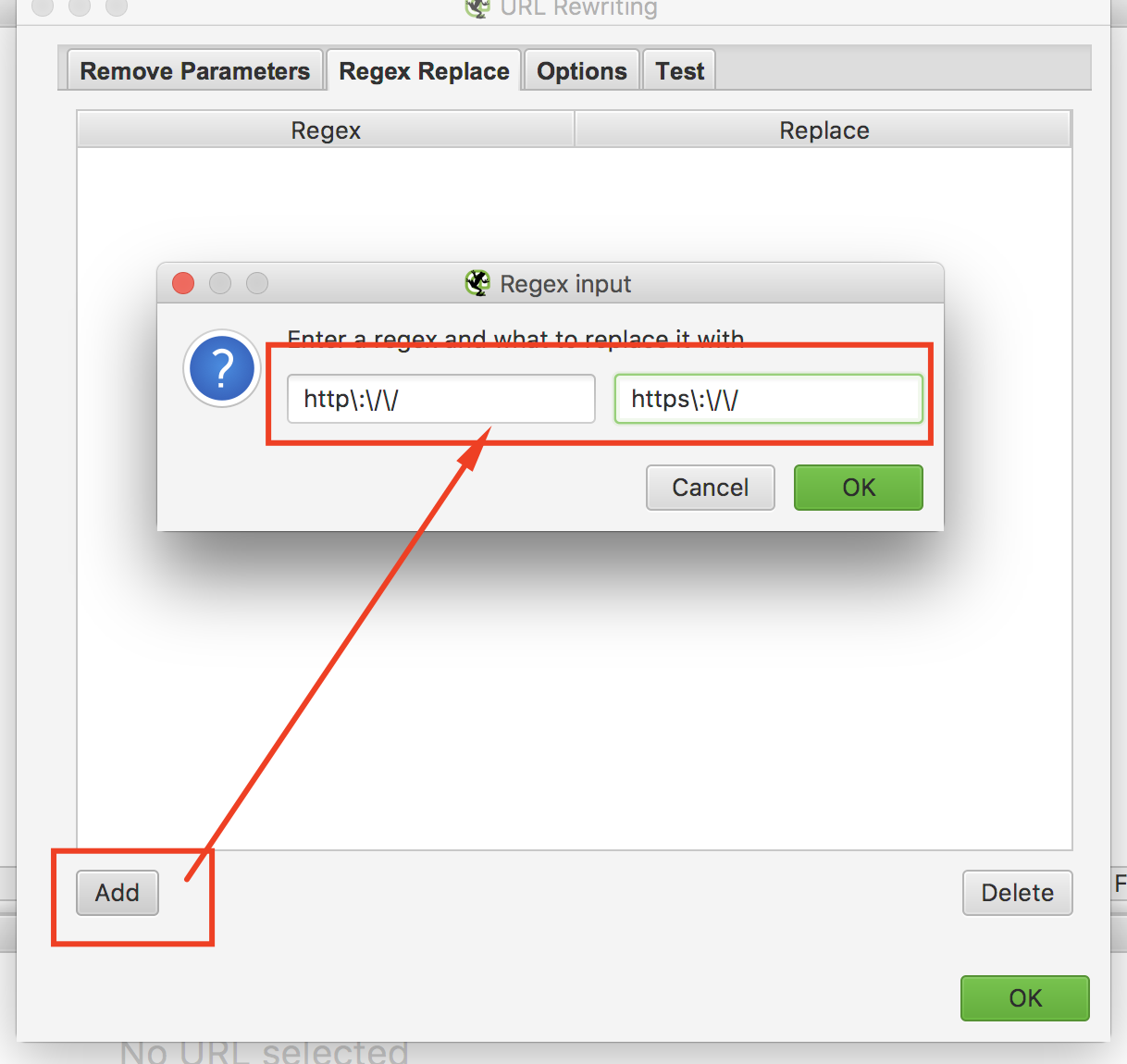
Рис. 3. Скриншот из сервиса Screaming Frog — Внедрение функции URL Rewriting
Дальше давим клавишу «ОК» и переходим во вкладку «Test». В данной вкладке сервис вам покажет, верно ли вы задали верховодило и как будут склеиваться зеркала. В нашем случаем обязан выходить таковой итог:
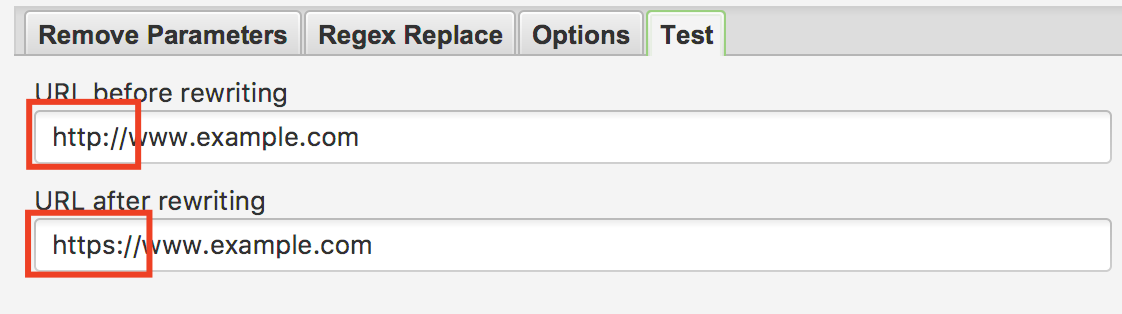
Рис. 4. Скриншот из сервиса Screaming Frog — Внедрение функции Test
Таковым же методом можнож склеивать странички с «www» и без «www», также задавать разные свойства, чтоб не выводить негодные странички(к образцу, странички пагинации).
Опосля всех операций безмятежно запускаем парсинг сайта без доборной перегрузки на систему.
2. Внедрение панели Яндекс.Вебмастер
В Яндекс.Вебмастер есть чрезвычайно удачный пункт сервиса - «Индексирование» — «Странички в поиске». Данный пункт наглядно указывает текущую индексацию сайта, также дубликаты страничек(то, что мы отыскиваем):
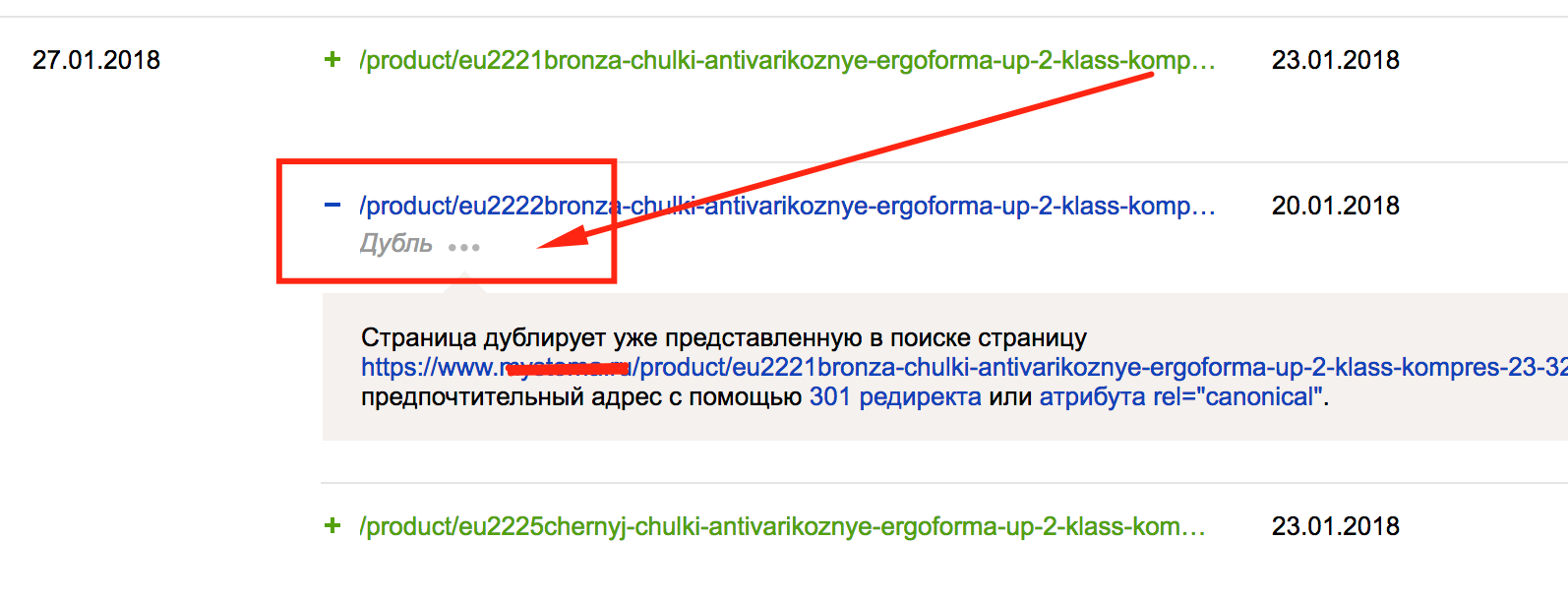
Рис. 5. Скриншот из панели Яндекс.Вебмастер — Внедрение функции Странички в Поиске
Для полного анализа дубликатов страничек рекомендуется выгрузить xls-файл всех страничек, которые находятся в поиске:

Рис. 6. Выгрузка страничек в поиске из панели Яндекс.Вебмастер
Раскрываем наш xls-файл и включаем фильтр: Данные – Фильтр:
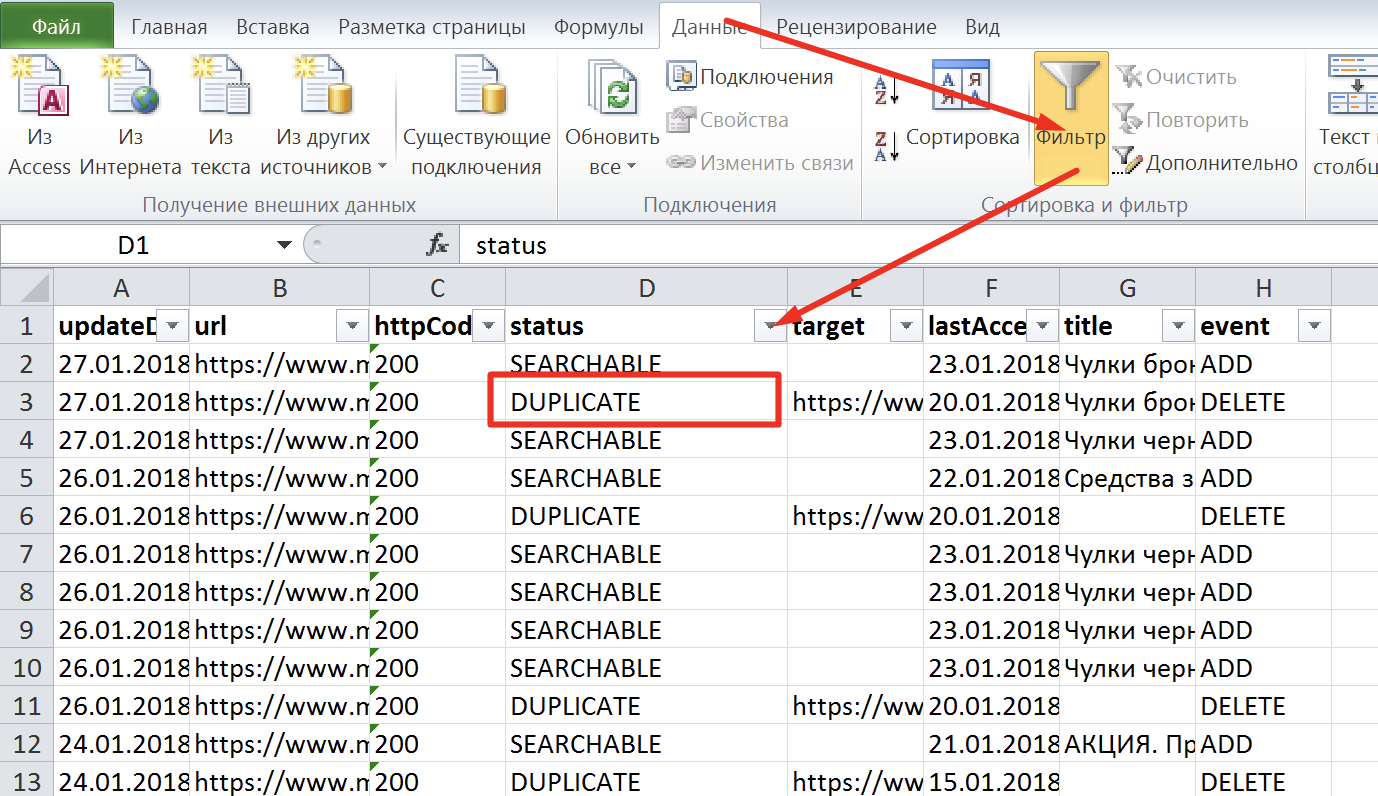
Рис. 7. Скриншот из xls-файла «Выгрузка страничек в поиске из панели Яндекс.Вебмастер»
В фильтре избираем «DUPLICATE», и перед нами будет перечень дубликатов страничек. Рекомендуется проанализировать каждую страничку или один тип страничек,(ежели, к образцу, это лишь карточки продуктов)на предмет дублирования.
К образцу: поисковая система может признать дубликатами схожие карточки продуктов с незначимыми отличиями. Тогда необходимо переписать содержание странички: главной контент, теги и метатеги, ежели они дублируются, или такие карточки склеить с поддержкою атрибута rel=”canonical”. Иные советы по избавлению от дубликатов страничек досконально описаны в пт 5.
3. Внедрение Google Search Console
Заходим в Google Search Console, избираем собственный сайт, в левом меню кликаем «Вид в поиске» – «Оптимизация HTML» и глядим такие пункты, которые соединены с термином «Повторяющееся»:
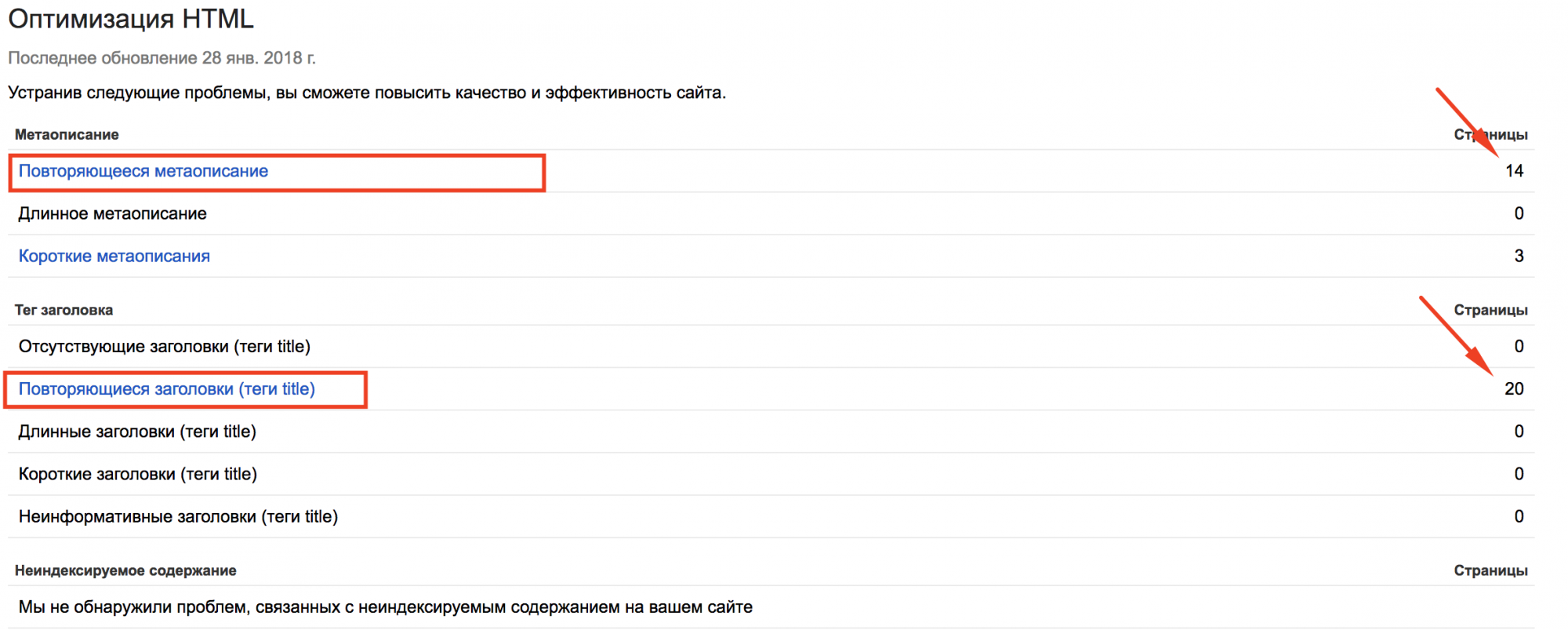
Рис. 8. Скриншот из панели «Google Console»
Данные странички могут не являются дубликатами, но проанализировать их необходимо и при необходимости ликвидировать трудности с дублированием.
4. Внедрение операторов поиска
Для поиска дубликатов также можнож применять операторы поиска «site:» и «inurl», но данный способ теснее обветшал. Его вполне заменила функция «Странички в поиске» в Яндекс.Вебмастере.
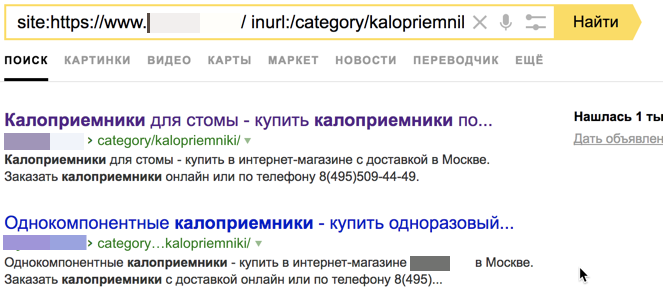
Рис. 9. Скриншот из поисковой выдачи – внедрение поисковых операторов
5. Ручной поиск
Для ручного поиска дубликатов страничек необходимо теснее владеть познаниями о том, какие дубликаты могут быть. Вручную традиционно проверяются такие типы дубликатов, как:
?URL-адрес с “/” и без “/” в конце. Проверяем первую страничку сайта с “/” и без “/” в конце в сервисе bertal. Ежели обе странички отдают код ответа сервера 200 ОК, то такие странички являются дубликатами и их необходимо склеить 301 редиректом
?прибавление в URL-адрес каких-то знаков в конце адреса или посреди. Ежели опосля перезагрузки страничка не дает 404 код ответа сервера или не настроен 301 Moved Permanently на текущую главную страничку, то перед нами, по сути, тоже дубликат, от которого необходимо избавиться. Таковая ошибка является системной, и ее необходимо решать на автоматическом уровне.
Как избавиться от дубликатов страничек: главные виды и методы
В данном пт разберем более нередко встречающиеся виды дубликатов страничек и варианты их устранения:
- Не склеенные странички с «/» и без «/», с www и без www, странички с http и с https.
Варианты устранения:
?Настроить 301 Moved Permanently на главное зеркало, непременно выполните нужные опции по выбору главного зеркала сайта в Яндекс.Вебмастер.
- Странички пагинации, когда дублируется текст с первой странички на все другие, при всем этом продукт различный.
Выполнить последующие события:
?Применять теги next/prev для вязки страничек пагинации меж собой;
?Ежели 1-ая страничка пагинации дублируется с главной, необходимо на первую страничку пагинации поставить тег rel=”canonical” со ссылкой на главную;
?Добавить на все странички пагинации тег:
< meta name="robots" content="noindex, follow" / > |
Данный тег не дозволяет боту поисковой системы регистрировать контент, но дает переходить по ссылкам на страничке.
- Странички, которые возникают из-за некорректно работающего фильтра.
Варианты устранения:
?Корректно настроить странички фильтрации, чтоб они были статическими. Также их необходимо верно улучшить. Ежели все корректно настроено, сайт будет дополнительно собирать трафик на странички фильтрации;
?Закрыть страницы-дубликаты в файле robots.txt с поддержкою директивы Disallow.
- Схожие продукты, которые не имеют существенных различий(к образцу: цвет, размер и т.д.).
Варианты устранения:
?Склеить схожие продукты с поддержкою тега rel=”canonical”;
?Воплотить новейший функционал на страничке карточки продукта по выбору свойства. К образцу, ежели есть несколько практически схожих продуктов, которые различаются лишь, к образцу, цветом изделия, то рекомендуется воплотить выбор цвета на одной карточке продукта, дальше – с других настроить 301 редирект на главную карточку.
- Странички для печати.
Вариант устранения:
?Закрыть в файле robots.txt.
- Странички с ошибочной настройкой 404 кода ответа сервера.
Вариант устранения:
?Настроить корректный 404 код ответа сервера.
- Дубли, которые возникли опосля некорректной смены структуры сайта.
Вариант устранения:
?Настроить 301 редирект со страничек ветхой структуры на подобные странички в новейшей структуре.
- Дубли, которые возникают из-за некорректной работы Яндекс.Вебмастера. К образцу, такие URL-адреса, которые кончаются на index.php, index.html и другие.
Варианты устранения:
?Закрыть в файле robots.txt;
?Настроить 301 редирект со страничек дубликатов на главные.
- Странички, к образцу, 1-го и такого же продукта, которые дублируются в различных категориях по отдельным URL-адресам.
Варианты устранения:
?Cклеить странички с поддержкою тега rel=”canonical”;
?Лучшим решением будет вынести все странички продуктов под отдельный параметр в URL-адресе, к образцу “/product/”, без привязки к разделам, тогда все продукты можнож раскидывать по разделам, не будут “плодиться” дубликаты карточек продуктов.
- Дубли, которые возникают при прибавлении get-параметров, различных utm-меток, пометок счетчиков для отслеживания эффективности маркетинговых кампаний: Google Analytics, Яндекс.Метрика, реферальных ссылок, к образцу, странички с таковыми параметрами как: gclid=, yclid=, openstat= и другие.
Варианты устранения:
?В данном случае необходимо проставить на всех страничках тег rel=”canonical” со ссылкой странички на саму себя, потому что закрытие таковых страничек в файле robots.txt может испортить корректному отслеживанию эффективности маркетинговых кампаний.
Устранение дублей дозволит поисковым системам лучше осмысливать и ранжировать ваш сайт. Используйте советы из данной статьи, тогда и поиск и устранение дублей не будет казаться трудным действием.
И повторюсь: маленькое количество дубликатов не так веско скажется на ранжировании вашего сайта, но великое количество(более 50% от общего числа страничек сайта)очевидно нанесет вред.
Комментариев: 0