

Проблематика
Допустим, мы имеем малюсенький сайт с 10 страничками. Нам бы хотелось, чтоб у нас было 10 кластеров запросов под каждую страничку. Как подобрать эти запросы?
Решение в лоб – это сбор маркерных запросов из Wordstat, позже парсинг поисковых подсказок, частотности запросов и последующая кластеризация всего «облака» по маркерам. Согласитесь – и длинно, и недешево. Вот бы был сервис, в который можнож выслать 10 маркерных запросов, а он бы возвращал 10 кластеров, да еще и с частотностью.
Классическая кластеризация
В общем виде кластеризация – это сортировка объектов по какому-то общему признаку. Двигаясь от знаменитого к новенькому, давайте осмотрим метод кластеризации по признаку схожести поисковых топов:
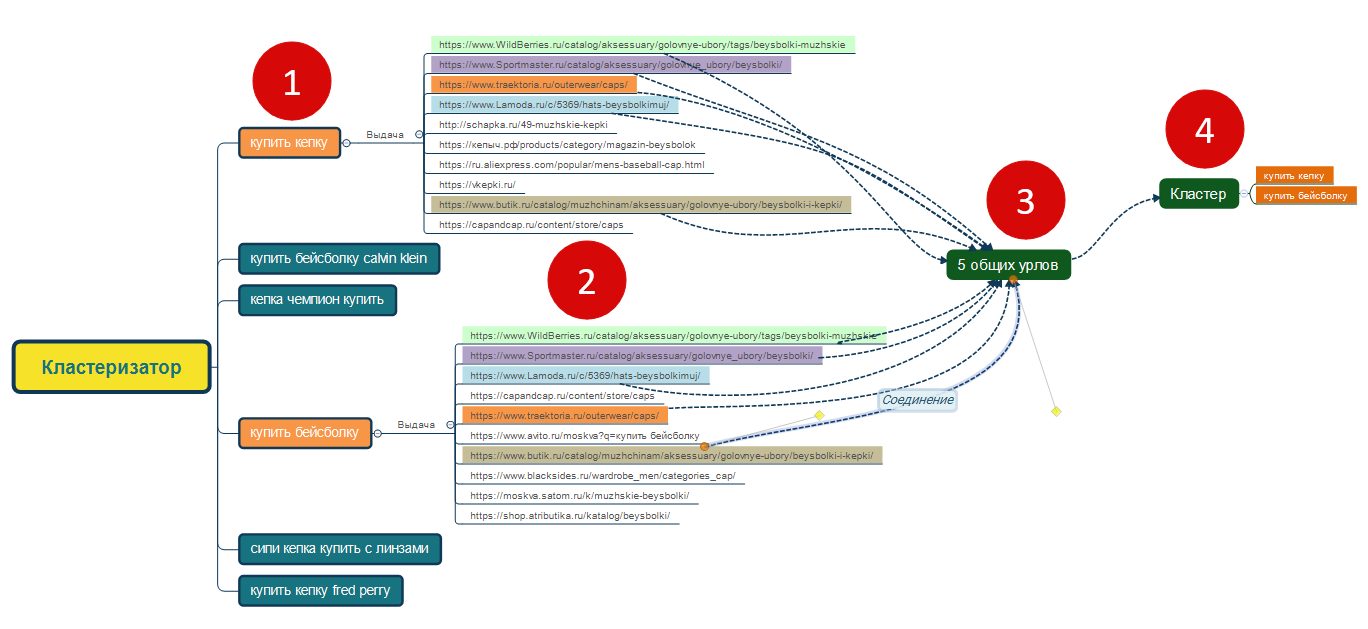
- на шаге 1 мы имеем перечень запросов в поисковике;
- на шаге 2 проверяется топ-10 по каждому запросу;
- на шаге 3 проверяется наличие общих url;
- на шаге 4 в один кластер объединяются запросы, у каких есть общие url.
Пример намеренно упрощен, чтоб было легче понять, что такое «кластеризация наоборот».
Кластеризация наоборот
Метод под заглавием «кластеризация наоборот» нельзя вполне именовать кластеризацией, он работает по-другому:
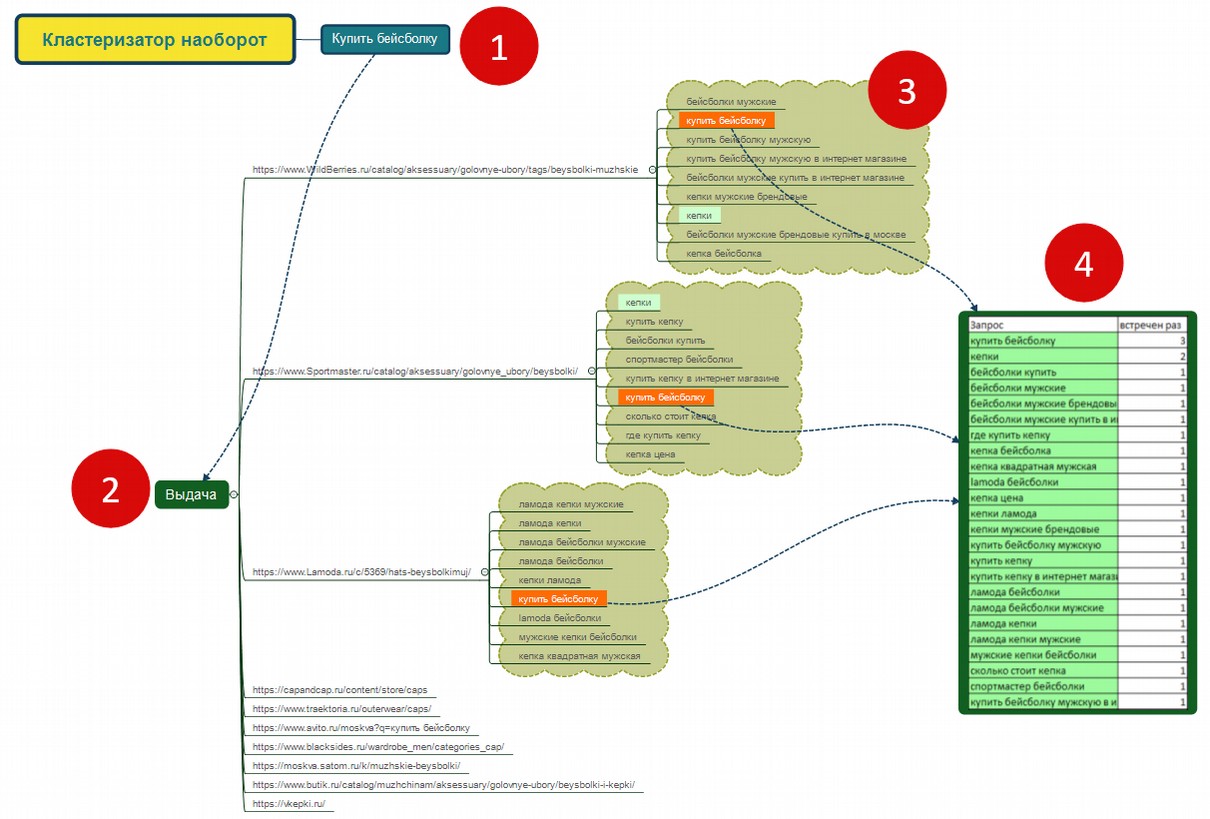
- на шаге 1 подается на вход запрос в поисковике;
- на шаге 2 проверяется топ-10 благодаря чему запросу;
- на шаге 3 получаем перечень запросов, по которым url встречается в топ 10 (подробнее про этот шаг будет ниже) ;
- на шаге 4 соединяем все запросы в один перечень. Он, окончательно, содержит дубликаты. Мы можем посчитать, сколько разов повторяется тот либо другой ключ, а позже отсортировать все ключи по данной цифре.
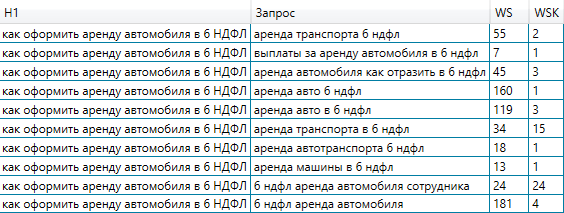
Для образца мы проверили выдачу по запросу «купить бейсболку», позже для каждого url получили перечень ключей, соединили перечни и посчитали встречаемость ключей. На скриншоте видно, что ключ «купить бейсболку» встречается 3 раза, ключ «кепки» – 2 раза, другие – по одному разу.
Еще есть 5-ый шаг, сообразно которому нам необходимо брать лишь вершину получившегося на шаге 4 перечня. Дело в том, что запросы, которые встречаются 1 разов, нас не интересуют – посреди их есть и брендовые запросы, и те, что в кластере будут смотреться неуместно. Вершиной числятся 1-ые 10 запросов перечня, они встречаются почаще всего. 10 запросов вполне довольно для первичной оптимизации одной странички.
Ключи на url
Но откуда брать запросы, по которым конкретный url находится в топе?Таковой инфы поисковая система не открывает, придется пользоваться платными сервисами:
- Ahrefs.com;
- Serpstat.com;
- Keys.so.
На базе заключительного (Keys.so) и работает программа, которая реализует этот метод.
KeysSoCollector
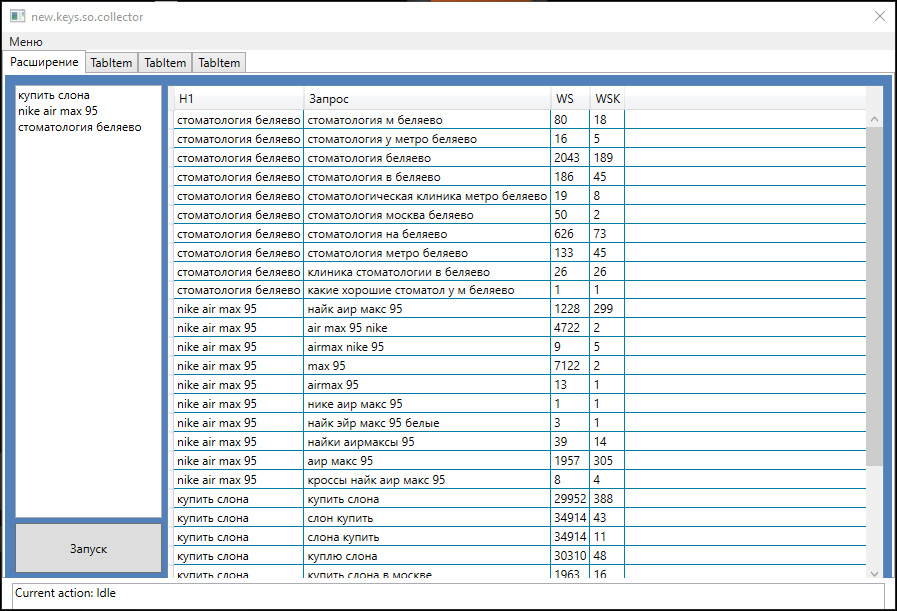
Скачать ее можнож тут, разархивируйте папку на десктоп. Для того чтоб все заработало, вам необходимо зайти в опции программы и заполнить текстовые поля:
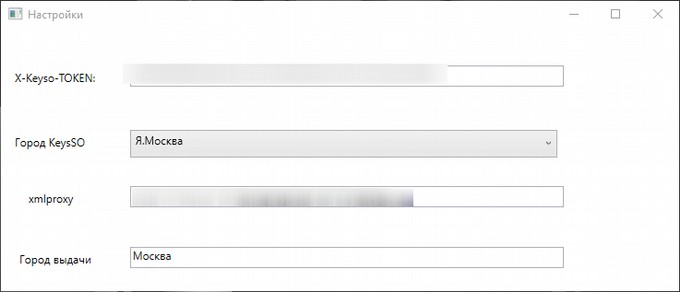
-
X-Keyso-Token – берите его из собственного кабинета keys.so.
-
Город KeysSo – это город базы ключевиков. Выбрать подходящий можнож из раскрывающегося перечня.
-
xmlproxy – это ваш адресок для совершения запросов к XMLProxy. Необходимо скопировать вполне всю строчку:

-
Город выдачи – это город выдачи Яндекса. В различных городках, как знаменито, выдача различается, потому необходимо написать с великий буквы ваш город без помощи других.
Задайте перечнем маркерные запросы в текстовое поле в левой доли программы и нажмите Пуск. Через некое время вы получите готовые кластеры запросов с их частотностью.
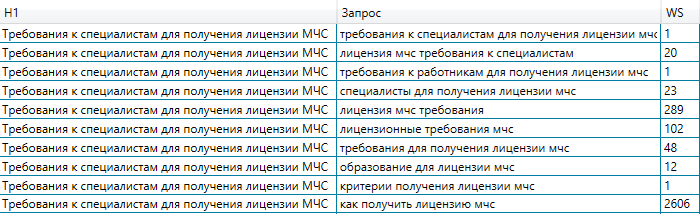
Образцы получившихся кластеров
Превосходства и недостатки
К превосходствам такового подхода можнож отнести:
- скорость сбора ключей;
- получение сходу ключей с их частотностью;
- простота подхода – всего пара шагов до готового результата;
- разнообразие ключей на выходе (не попросту перестановки слов 1-го ключа) ;
- получившийся кластер дает представление о том, какой интент запроса исходя из убеждений ПС;
- сбор запросов на любом языке. Ежели сделать реализацию этого метода с внедрением Serpstat и Google, то можнож собирать запросы на любом языке.
Про заключительный пункт стоит сказать подробнее. Дело в том, что объект поиска Яндексу приходится разгадывать, потому что большая часть запросов мультиинтентные. Возьмем для образца запрос «поло». Что желал юзер?Аква поло?Либо рубахи поло?Либо ошибся в слове «пол». Либо это машинка Volkswagen Polo?Проверим.
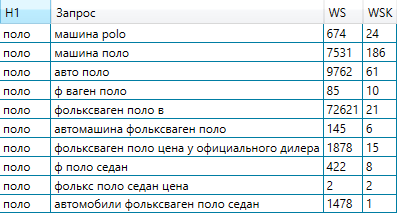
Видите ли, кластер полностью про Volkswagen Polo. Так вышло потому, что в выдаче Яндекса благодаря чему запросу 10 url про машинку. Осмотрим наименее явный пример:
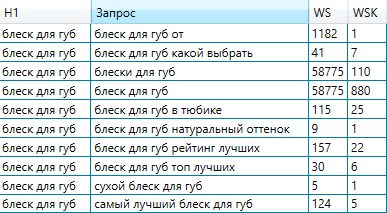
Чрезвычайно нередко по таковым запросам почти все ждут узреть коммерческую выдачу, но на самом деле она является информационной. Таковым образом можнож живо и точно анализировать интенты, не прибегая к сервисам проверки типа запросов.
К изъянам относятся:
- Ограничение на количество ключей в кластере. Оно существует, потому что 1-ые 10 ключей перечня, обычно, превосходно дополняют главной маркер. Но далее начинаются случайные запросы, которые сделают кластер «грязным», и его придется вычищать. Экспериментально выявлено, что 10 запросов – это наилучшее количество.
- Время от времени можнож получить меньше 10 запросов в кластере:
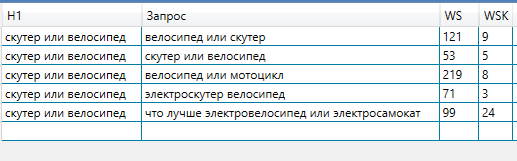
Это происходит потому, что не набралось 10 ключей для анализа. Такое вероятно в тех вариантах, когда семантика не предугадывает контраста и когда url в выдаче находятся по одному-двум ключам.
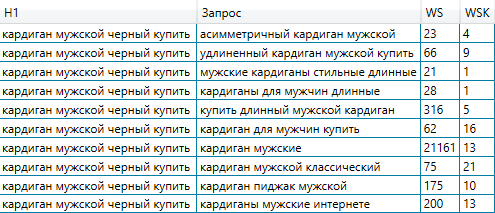
- Время от времени кластер выходит чрезвычайно запятанным и нерелевантным главному маркеру. Сначала это соединено с тем, что сама выдача нерелевантна запросу. На образце ниже мы видим кластер, который состоит из разношерстных запросов про кардиганы, но нам-то необходимы были запросы про мужской темный кардиган.
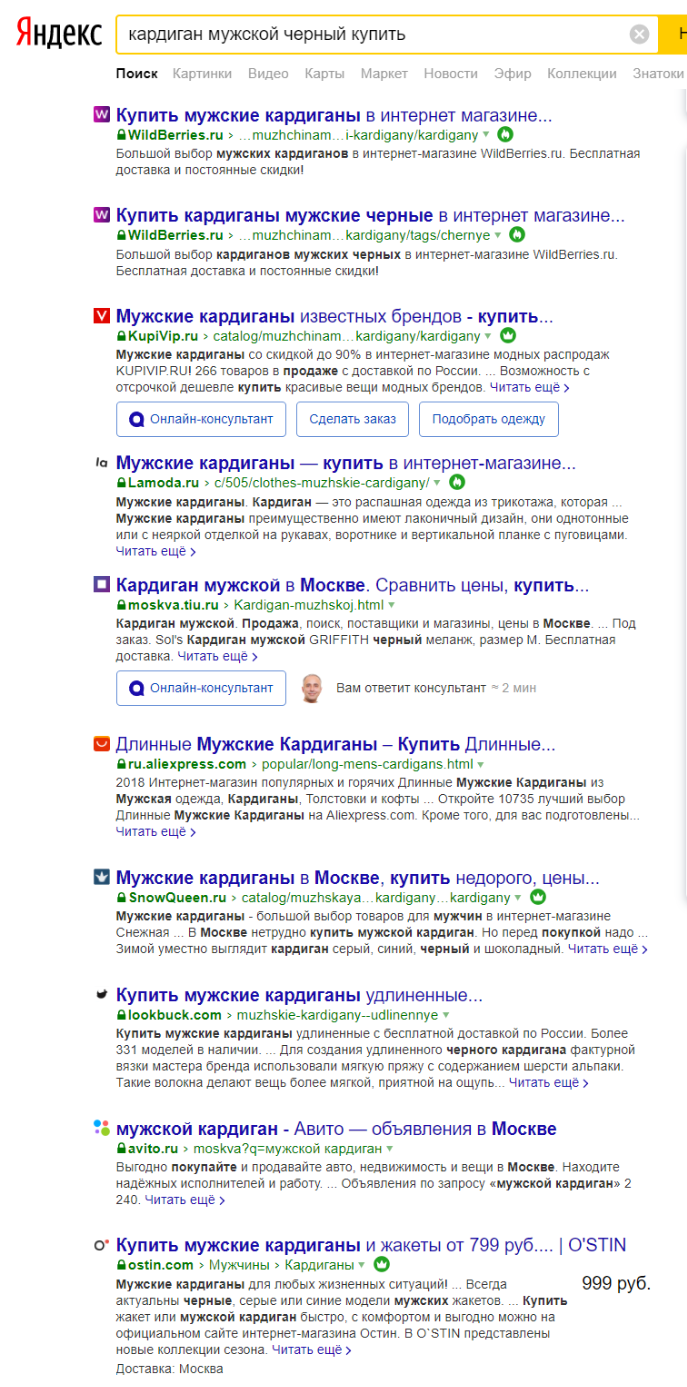
Ниже приведена органическая выдача по запросу «кардиган мужской темный купить». Там мы видим, что лишь Wildberries сделали отдельную страничку под этот запрос. Другие ответы нерелевантны – быстрее всего, у Яндекса просто нет релевантных ответов на этот запрос.
Как можнож доработать алгоритм
Избирать перестановки по частотности
К примеру, запросы «купить кроссовки в москве» и «кроссовки в москве купить» – это, по сути, перестановка одних и тех же слов. В таком случае можнож было бы разговаривать о том, что это один и этот же запрос, который встречается 2 раза. И в итоговом перечне отдавать самую частотную перестановку.
Недописанные запросы
В хоть какой базе ключевиков встречаются запросы, с которыми SEO-специалист не работает. К примеру, запрос «блеск для губ от». Их просто выделить, потому что они кончаются предлогом либо союзом.
Выбор языка
Когда мы разговариваем про парсинг выдачи Google, то мы, окончательно, помним, что это мультиязычный поиск, он работает во всех странах.
Ежели так, тогда мы можем применять этот метод для того, чтоб смонтировать кластер запросов на чужом языке, к примеру французском.
Комментариев: 0