
Эволюция поисковых систем предъявляет новейшие требования к написанию текстов для сайта. SEO-копирайтинг уходит в прошедшее, на замену прибывает LSI-копирайтинг. Досконально рассказываем, что это и как работает.
Задачка поисковых систем — отыскать информацию, которая более точно отвечает запросам юзера. Для этого машинки обязаны были выучиться распознавать смысл на базе содержания, но не совсем лишь по отдельным «маякам» — запросам в поисковике.
Классическая схема «запрос-документ» стала неактуальной из-за заспамленности большинства тем. Потому ей на замену пришли методы латентного семантического анализа, а потом нейросети. В ответ профессионалы SEO стали внедрять LSI-копирайтинг.
Термин
LSI-копирайтинг — метод написания текстов на базе анализа синонимов запроса в поисковике и сопутствующих ключевиков.
Цель — повышение релевантности, полезности, актуальности и достоверности мат-ла. LSI-копирайтинг подсобляет поисковым системам лучше осмысливать смысл и содержание текста. В итоге сайт может попасть на 1-ые странички выдачи, даже имея малое количество ключевиков.
На практике это означает, что в тексте необходимо использовать синонимы главного запроса, сопутствующие ключевики и доп фразы из смежных тем. Это дозволит вполне охватить и раскрыть тему. Таковой контент оценят и юзеры, и поисковые системы.
История
В 1988 latent semantic analysis(LSA)получил патент U.S. Patent 4,839,853. Создатели способа — группа инженеров-исследователей: Скотт Дирвестер, Сьюзен Дюмэ, Джордж Фурнаш, Ричард Харшман, Томас Ландауэр, Карен Lochbaum и Линн Стритер.
Сначало LSA применяли для выявления семантической структуры и автоматического индексирования текста. Потом — для построения когнитивных моделей и представления баз познаний. В США метод употреблялся для проверки свойства обучающих методик и познаний школьников.
Суть метода
LSA, латентный семантический анализ — метод обработки инфы на природном языке. Он анализирует связь меж коллекциями документов и определениями, которые в их встречаются. Латентный семантический анализ сравнивает запросы и документы соответственно теме. Это дозволяет выявлять тайные ассоциативные и семантические связи.
LSI — аббревиатура от latent semantic indexing, с британского — латентное семантическое индексирование. Это метод применения LSA в области поиска инфы.
Проще разговаривая, LSA дозволяет машинкам осмысливать смысл и содержание документа. А при ранжировании уравнивает «веса» различных по написанию, но недалёких по смыслу слов. Таковым образом структурируются синонимы и запросы идентичной темы.
База системы — терм-документная матрица, разбор которой и является LSA. Терм-документная матрица представляет из себя таблицу, в какой совмещаются «термы»(слова, фразы, определения)и документы. Строчки подходят документам, а столбцы — терминам. Число означает количество пересечений.
Документ 1 | Документ 2 | Документ 3 | Документ 4 | Документ 5 | Документ 6 | |
Корабль | 1 | 0 | 0 | 0 | 0 | 0 |
Лодка | 0 | 1 | 0 | 0 | 0 | 0 |
Океан | 1 | 1 | 0 | 0 | 0 | 0 |
Вояж | 1 | 0 | 0 | 1 | 1 | 0 |
Путешествие | 0 | 0 | 0 | 1 | 0 | 1 |
Процесс семантического анализа сходствен работе простейшей нейросети — машинка отыскивает пересечения связи меж 2-мя слоями данных. Матрица обрисовывает частоту, с которой встречаются определения в коллекциях документов.
LSI в методах поисковых систем
1-ое упоминание LSA в поисковых системах соединено с методом Panda от Google. Обновление ставило себе цель — отыскать и понизить количество контента низкого свойства, который был сотворен с целью манипуляции поисковой выдачей. Метод был запущен в феврале 2011, а теснее в 2012 году возникли первые упоминания о LSI-копирайтинге.
Конечно новейшие требования к качеству текстов сформировались к 2013 году. В это время Google запустил новейший метод — Hummingbird(«Колибри»). Главное отличие новейшего способа — поиск стал осмысливать запросы в поисковике разговорного типа. Google выучился находить нужные документы, отталкиваясь от семантических связей, но не попросту по запросам.
Яндекс схватил эстафету в ноябре 2016 года — запустил метод «Палех». Его задачка — распознавать низкочастотные и трудные запросы из «длинного хвоста». Другими словами осмысливать запросы в разговорном ключе. Общественная масса таковых запросов сочиняет порядка 40% от размера текста.
Для работы способа были применены нейросети и машинное обучение. Подробнее о механике и принципах работы способа можнож прочесть в блоге Яндекса на Хабрахабре. Введение в работу «Палеха» подогрело энтузиазм к LSI-текстам в русскоязычном вебе.
Весной 2017 года Яндекс вводит «Баден-Баден» — новейший метод определения текстов, которые перенасыщены ключевиками. Тыщи страничек попадают под фильтр и понижаются в выдаче, условием возврата трафика величается отказ от SEO-текстов.
Осенью 2017 Яндекс запускает «Королев» — метод поиска на базе нейросетей. По заявлению Яндекса, метод «...сопоставляет смысл запросов и веб-страниц...». Новейший алгоритм работает на нейросетях, но при всем этом не отменяет LSI, а увеличивает сложившиеся тенденции. Сейчас писать SEO-тексты нет никакого смысла — заместо ТОПа можнож получить фильтр за переоптимизацию.
Отличие LSI от SEO-копирайтинга
Для удобства используем сравнительную таблицу
Отличия | SEO-тексты | LSI-тексты |
Цель | Написать текст с подходящими ключевиками и определенным числом вхождений | Вполне удовлетворить запрос пользователя |
Задача | Вписать ключевики с предопределенной плотностью и расположением | Охватить весь диапазон ассоциативных связей, осмотреть делему со всех сторон |
Нахождение ключевиков в тексте | В заголовках, в первом абзаце, выше по тексту | Не важно |
Оформление статьи | Непринципиально | Необходимо |
Методы оценки свойства текста | Техно неповторимость, плотность вхождений, частота применения слов на определенный размер текста | Смысловая неповторимость, полезность, удовлетворенность пользователя |
Размер текста | От 2000 символов с пробелами | Столько, сколько необходимо для раскрытия темы. На практике 5000–10 000 символов и больше. |
Как видим, главное отличие — отход от чисто технических характеристик текста к здоровому смыслу: выгоде, удобству читаемости. Можнож сказать, что это эволюция SEO-копирайтинга — мат-лы создаются для жителей нашей планеты, но не для роботов.
Это итог того, что сейчас поисковые машинки расценивают релевантность контента по смыслу. Учитывается контекст, уместность, семантические варианты запросов и их свита. Совместно с поведенческими факторами это дозволяет расценивать качество текста и потребности читателей.
Превосходства и недостатки
Преимущества
Те, кто смог приспособиться к новеньким требованиям поисковых систем, получают определенные превосходства.
- Возрастает семантическое ядро. Все LSI-фразы — это доп, низкочастотные ключи по той же теме.
- Возрастает «длинный хвост» запросов и трафик. Используйте сопутствующие запросы и получите гостей по широкому диапазону редких ключевиков.
- Улучшаются поведенческие причины. Большая, нужная статья завладеет больше читательского внимания и медли. Даже просто на то, чтоб пробежаться по заголовкам и разобраться, пригодится время.
- Вырастет количество соц сигналов и природных ссылок. Полезным мат-лом делятся, о нем говорят, берегут у себя на страничках, чтоб использовать в дальнейшем.
- Возрастут позиции в поиске по частотным фразам. «Длиннющий хвост» запросов подтянет за собой конкурентноспособные ключевики, в этом ему посодействуют поведенческие и социальные причины.
- Сайт не попадет под фильтр. Все современные методы нацелены на отсев напрасных текстов, заточенных под роботов. Внедрение принципов LSI-копирайтинга дозволит недопустить сходственной ситуации.
- Проще структурировать сайт. Ежели ранее приходилось творить несколько страничек для охвата синонимов или сопутствующих запросов, то сейчас можнож создать одну страничку.
LSI-копирайтинг просит сурового вложения труда как SEO-специалиста, так и копирайтера. Но этот труд окупится сторицей. Вы получите стабильное нахождение в ТОПе и внимание юзеров.
Недостатки
Невзирая на вышеупомянутое, LSI — не панацея и имеет ряд изъянов:
- Модель работает на дозволении, что у слова есть всего одно значение.
- Текст рассматривается просто как набор слов, взаимосвязи и порядок игнорируются.
- Смысл текста не постоянно быть может буквальным, не учитывается сарказм, драматичность, иносказания и т.п.
- Часть данных пропадает во всяком случае. Это происходит, потому что сингулярное разложение дозволяет работать лишь с самыми означаемыми данными терм-документной матрицы.
Но даже с сходственными изъянами метод LSI превосходит существовавшие до этого методы индексации. А внедрение нейросетей дозволяет обучать поисковые машинки еще прытче и эффективнее.
Требования к LSI-текстам
К современным мат-лам предъявляются определенные требования.
- Выгода и достоверность. Необходимо раскрыть тему — текст обязан предоставлять юзеру настоящий ответ.
- Насыщенность LSI-фразами и наличие запросов в поисковике. Необходимо использовать ключевики, доп слова из темы и сопутствующие запросы.
- Простота изложения. Стиль и терминология подбираются таковым образом, чтоб текст был понятен рядовому юзеру.
- Структура. Точная структура и иерархия упрощают усвоение мат-ла, читатель получает возможность «просканировать» документ и понять о чем речь с первого взора.
- Ритм текста. Рекомендуется чередовать длинноватые и краткие предложения. Это восоздает определенную динамику, которая привлекает читателя.
- Грамотность и достоверность инфы. Не обязано быть фактических и грамматических ошибок. Недостоверность определит юзер, а оплошности — поисковые системы. И те, и иные сделают вывод о низком качестве текста.
Подведем итог. Существует спрос на высококачественные тексты экспертного уровня. Они обязаны владеть доборной ценностью для юзеров и поисковых машин, но не совсем лишь содержать в себе ключевики.
Как создать LSI-текст
Этапы работы:
- Смонтировать семантическое ядро из главных запросов.
- Подобрать LSI-фразы — сопутствующие запросы и доп слова из темы.
- Составить техзадание для копирайтера. Упор делать на качество текста, но не вхождения тех или других слов. Плотность, тошнота, частота вхождения и остальные технические характеристики текста не главны. Главнее, чтоб тема была раскрыта.
- Готовый текст используйте для творения плана странички — решите, как лучше использовать зрительный контент.
LSI-ключи
Распознают два вида ключей:
- Релевантные — слова из темы главного ключа, которые дополняют и уточняют его. Также сюда относятся фразы, которые имеют непосредственное отношение к теме статьи. Наличие таковых фраз в статье дозволяет понять, как тема раскрыта.
- Синонимичные — синонимы главного запроса. На их делается упор при базисной оптимизации текста. Это дозволяет не творить доп страничек и завлекать отраслевой трафик на одну страничку.
LSI-запросы можнож использовать:
- В анкорах входящих ссылок.
- В заключении или вступлении статьи.
- В окружающем тексте обратных и входящих ссылок.
- В заглавиях изображения, подписях и ALT.
- В заголовках и метатегах.
Главно не переусердствовать не забывать о главном запросе. Довольно единственного упоминания в тексте.
Приборы для сбора LSI-фраз
Сейчас существует достаточное количество способов подобрать LSI-фразы.
Подсказки поисковых систем
В Яндексе можнож подобрать слова, ежели использовать различные разновидности написания.
В Google ситуация сходная.
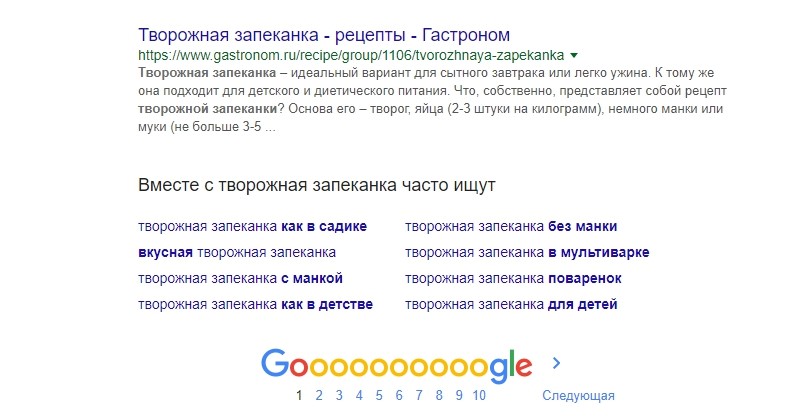
Блоки «Совместно с..» и «… нередко ищут»
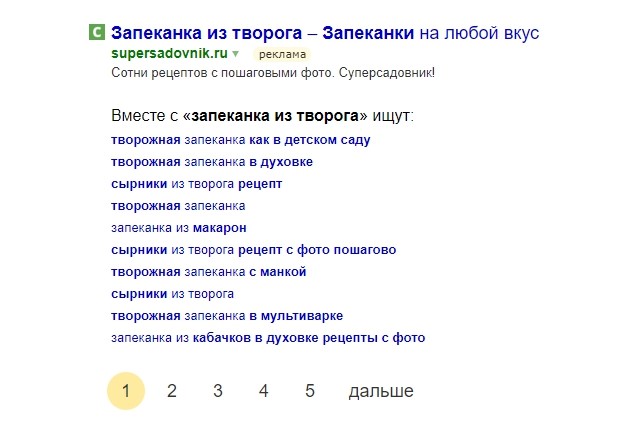
Статистика запросов Яндекс и Google
У обоих «поисковиков» есть собственная статистика ключевиков. Для подбора LSI-фраз можнож пользоваться ними. Это безвозмездно, но длинно. В Яндексе — это сервис Вордстат, а в Google — Google Keyword Planner. В заключительном работать можнож лишь из аккаунта Google AdWords.
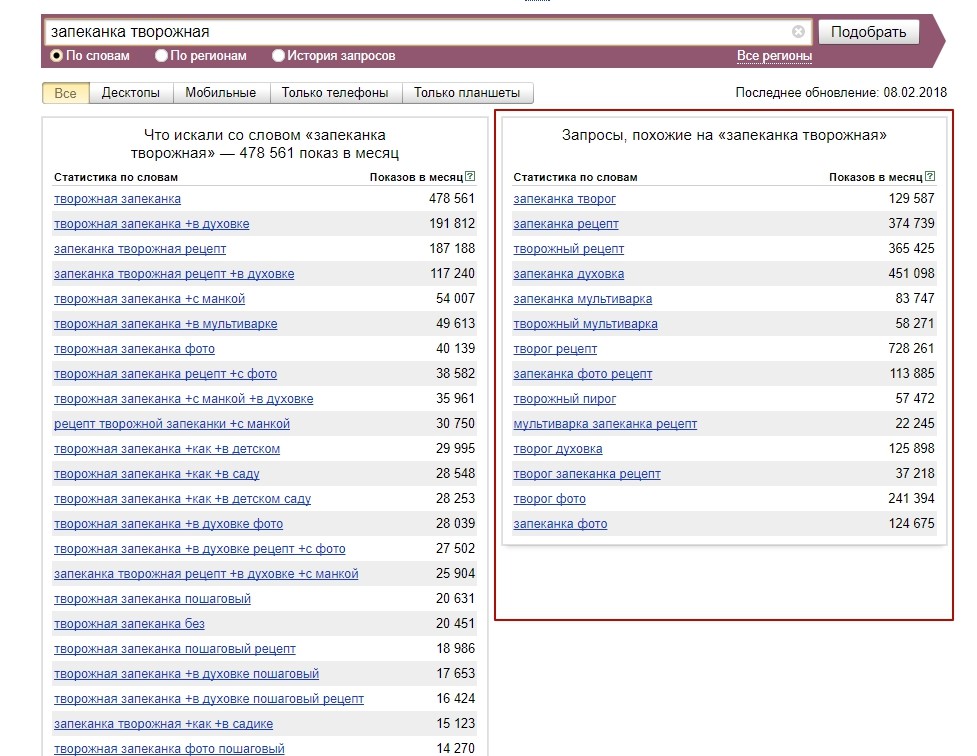
Pixel Tools
Сервис доступен опосля регистрации. Нам нужен раздел «ТЗ для копирайтера». Вбиваем запрос и получаем тематические слова. В разы прытче, чем при ручном сборе из поиска, но просит оплаты.
Идентичные способности имеют Megaindex и Serpstat. Два сервиса платные.
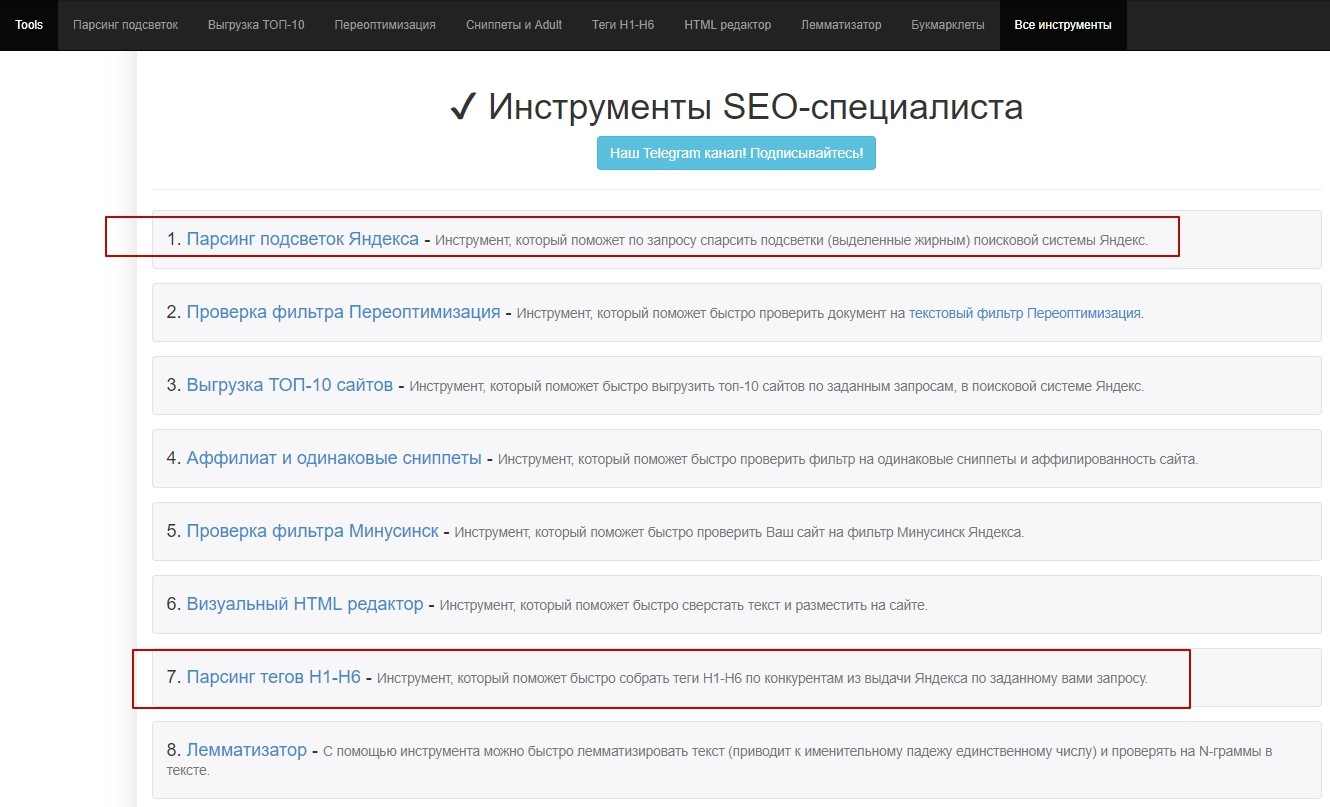
Arsenkin Tools
Набор безвозмездных приборов для работы SEO-специалиста от arsenkin.ru. По нашей теме дает сходу два сервиса: «Парсинг подсветок Яндекса» и «Парсинг тегов H1–H6». 1-ый поможет подобрать сопутствующие запросы, 2-ой — проанализировать структуру и распределение «ключей» соперников.
Ubersuggest tool
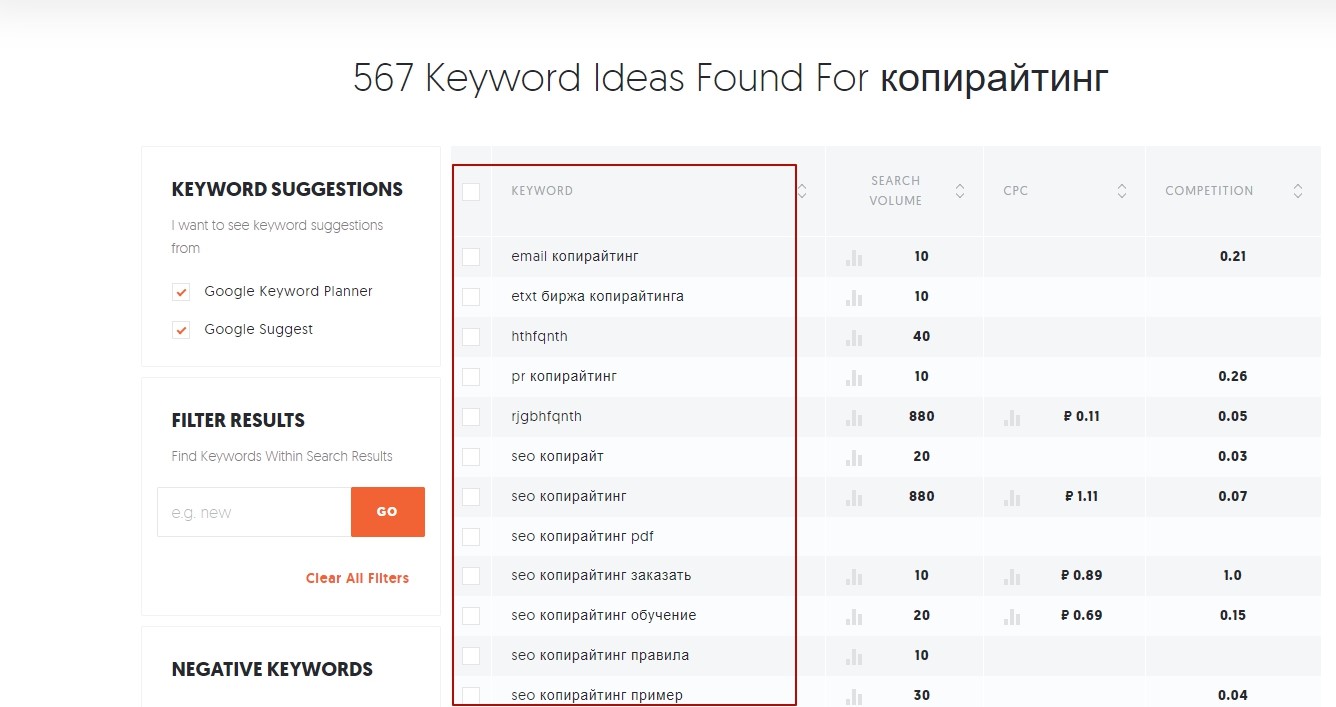
Для глубочайшей проработки LSI-фраз советуем пользоваться обслуживанием Ubersuggest tool. Сервис довольно прост в использовании и выдает довольно много вариантов доп слов.
Видеогайд по приборам для сбора LSI-фраз от Сергея Кокшарова
Творение структуры
Скелет хоть какой статьи — структура. Конкретно она дозволяет с первого взора оценить качество. Текст обязан иметь иерархию и покоряться внутренней логике. Доли статьи не обязаны противоречить друг другу.
- Статья обязана содержать заглавия и подзаголовки, маркированные перечни и таблицы. Ежели это страничка сайта, то стоит предугадать размещение отдельных частей: клавиш, форм заказа, фото.
- Заголовок обязан отражать главную идею мат-ла, заглавия второго уровня — развивать тему в различных качествах. Подзаголовки и заглавия третьего уровня указывают на частности или какие-то подробности.
- Заголовок и абзацы образуют, так именуемые блоки. В каждом блоке быть может несколько абзацев. Абзац содержит от 3-х до 6 строк и открывает одну определенную мысль. Краткие абзацы творят чувство легкого, динамичного текста.
- Иерархию заголовков можнож создать, делая упор на ключевики. Их необходимо сгруппировать по смыслу. В статье идите от общего к приватному — получится точное и логичное повествование.
Традиционно высокочастотные запросы дотрагиваются общей инфы. Группа среднечастотников даст возможность поглубже раскрыть тему. А низкочастотники дозволят охватить аспекты, которые занимательны юзерам.
Пример проработки структуры статьи

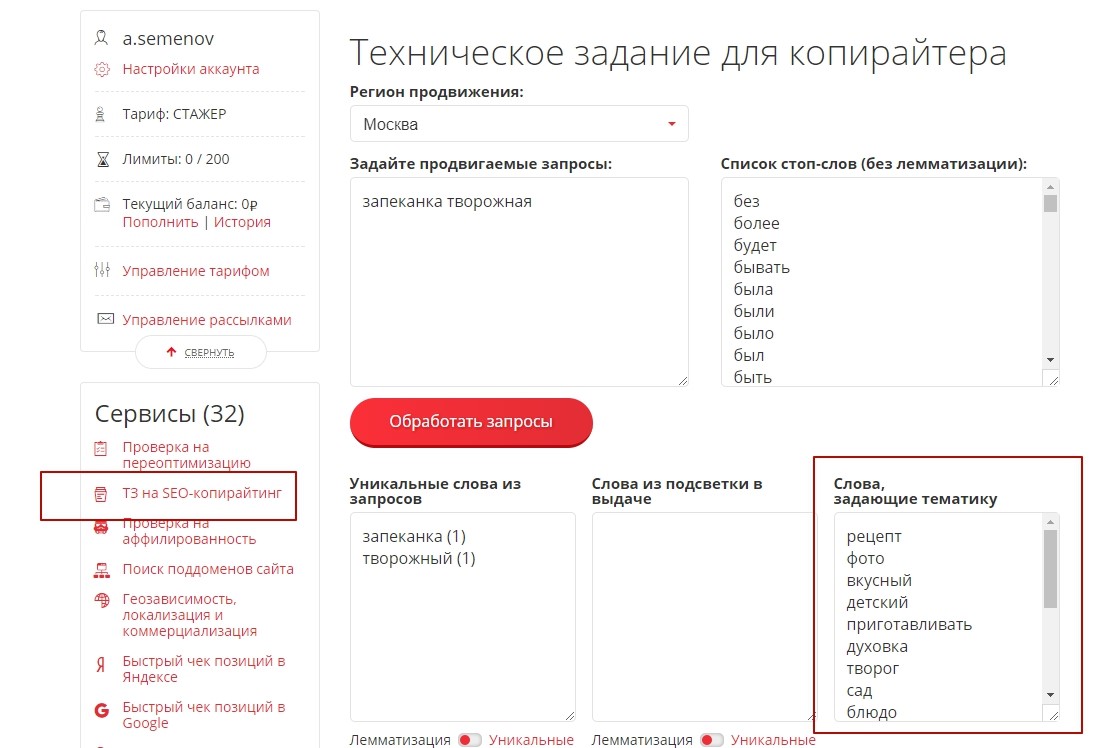
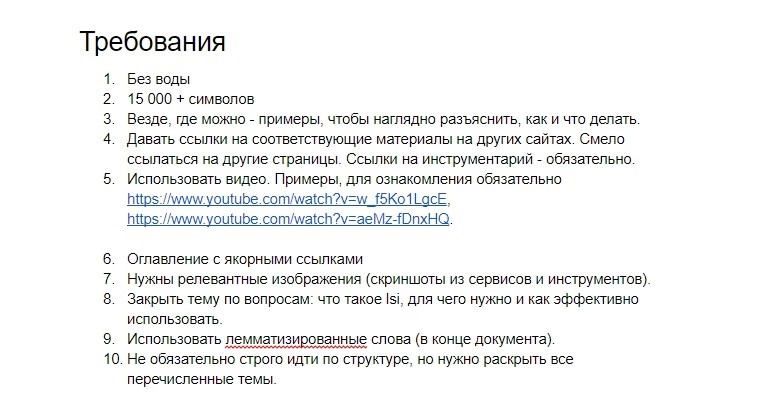
Постановка технического задания
Техническое задание стоит оформлять так, чтоб у копирайтера не появлялось вопросцев. Опишите требования очень досконально и верно. Чем лучше вы подготовитесь, тем меньше придется переделывать. И учтите, что для LSI-копирайтинга требуются профессионалы более высочайшего уровня. Образцово, ежели копирайтер имеет собственный опыт в обрисовываемой теме.
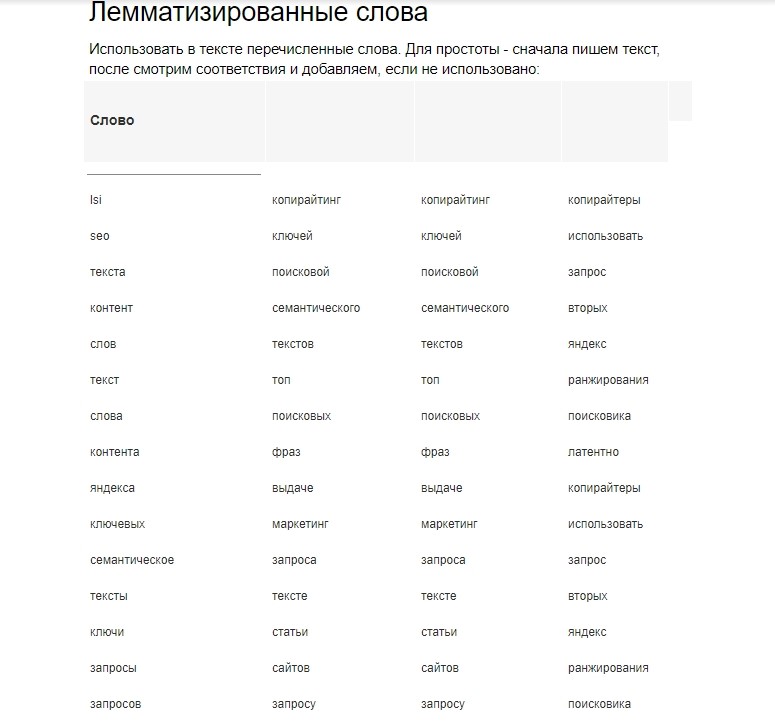
Пример ТЗ
Набор лемматизированных слов
Выбор исполнителя
Есть несколько подходов к написанию превосходного LSI-текста:
- Обратиться к знатоку, попросить осмотреть тему со всех сторон, поведать о аспектах. Таковым образом, LSI-фразы теснее будут в тексте, или их можнож будет щепетильно добавить.
- Отдать задание копирайтеру. Попросить вписать главные запросы в статье и заголовках, а сопутствующие запросы использовать для раскрытия темы.
- Иной вариант — отдать копирайтеру главные ключи, а сами LSI-фразы добавить, когда текст будет написан.
- Заказать в агентстве. Вам не придется собирать техническое задание, копирайтеры в агентстве работают по обкатанным схемам — их не придется обучать или переделывать работу.
Сопоставление LSI и SEO-текста
Пример текста с включением LSI-фраз. Это часть великого текста для странички сайта. Рассматриваются все виды съемной тонировки. Отмечаются необыкновенности каждого вида.

Пример классического SEO-текста. Проставлено несколько нужных вхождений с предопределенной плотностью. Место меж ключевиками заполнено общими, ничего не означающими фразами. Имитация информативного текста.

Нередкие вопросцы по LSI
Ежели вы что-то не сообразили или у вас возникли вопросцы, поглядите видео с Сергеем Кокшаровым. В ролике он отвечает на вопросцы SEO-специалистов.
Вопросы-ответы от Сергея Кокшарова
Выводы
Время от времени поднимается вопросец о необходимости подбора LSI-фраз, ведь по логике, довольно написать текст экспертного уровня. Но тут не многие так просто — невероятно всего лишь «прикинуть» в голове весь диапазон сопутствующих слов. Поисковые системы анализируют громадные базы данных, без их статистики ключевиков вы наверное что-нибудь упустите.
Главная задачка LSI — фильтрация мусора и определение смысла текста. Конкретно на ранжирование она влияет опосредованно. Но в критериях твердой конкуренции необходимо прорабатывать сайт вполне. Так как время от времени конкретно мелочи могут отдать решающее превосходство.
LSI-копирайтинг — не образцовый метод, но имеет ряд превосходств: дозволяет не попасть под текстовые фильтры и улучшить ветхие мат-лы. Переработка текстов дает возможность вывести сайт из-под санкций и прирастить посещаемость сайта.
Латентный семантический анализ и индексирование — явление теснее свершившееся. Более того, поисковые системы теснее подключили к собственной работе нейросети и машинное обучение. Логическим продолжением таковой эволюции будет искусственный интеллект в информационном поиске.
Комментариев: 0