
Не так давно на SEOnews вышла статья о методе расчета части небрендового трафика из поисковых систем. В комментах я кратко поделился своим методом получения данных, который заинтересовал читателей. Что ж, попробую поведать о нем подробнее.
Чтоб не напрягать себя сбором данных из различных интерфейсов систем аналитики, воспользуемся примечательной R Studio. Для начала короткая справка из Википедии.
R — язык программирования для статистической обработки данных и работы с графикой, также вольная программная среда вычислений с открытым начальным кодом в рамках проекта GNU.
Нам же будет нужно минимум его способностей.
Опустим подробности установки R и приступим к выгрузке данных. Для работы нам пригодятся последующие библиотеки:
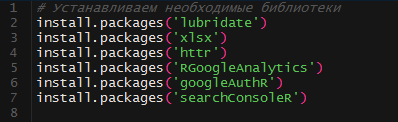
Загружаем и устанавливаем их один разов. При последующих пусках эта часть скрипта нам не пригодится. RGoogleAnalytics была удалена из CRAN, но есть ее архив, который можнож вручную распаковать в подходящую директорию. Ссылка на библиотеку: https://github.com/Tatvic/RGoogleAnalytics(здесь же можнож будет отыскать всю подходящую документацию по формированию запросов).
Подключаем установленные библиотеки:
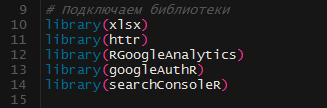
Lubridate приобщается автоматом.
Чтоб возникла возможность выгружать из Google Search Console наиболее 5000 рядов, прописываем последующие функции для библиотеки:

Дальше необходимо получить client id и client secret для работы с API Google Analytics. Для этого необходимо зарегистрировать свое прибавление тут.

Запишем даты в переменные, которые будут дальше употребляться во всех запросах к API(формат – YYYY-NN-DD). При следующей работе в идеале необходимо будет задавать лишь их:

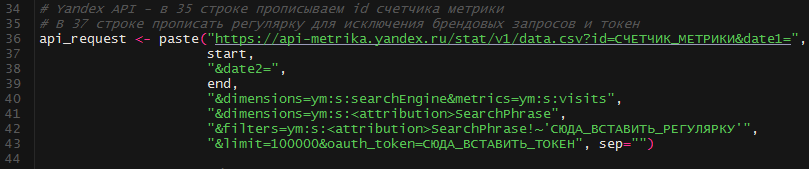
Формируем запрос к API Яндекса. По сути, это обыденный GET запрос.
В 36 строке необходимо указать номер счетчика метрики.
В 42 строке – постоянное выражение, исключающее брендовые запросы, где маски разделяются вертикальной чертой. К примеру ‘бренд|brand|брэнд’
В 43 строке необходимо вставить токен. Аннотации по получению токена можнож отыскать тут.
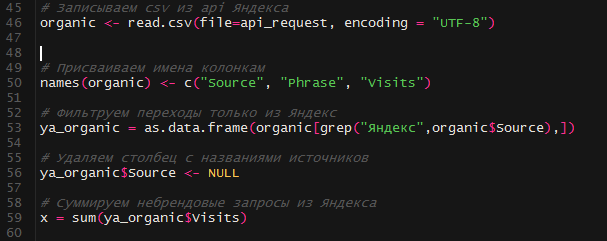
Дальше несколько обычных манипуляций, при поддержки которых мы обрабатываем приобретенные данные по небрендовому трафику Яндекса и сумму записываем в переменную «х».
Часть этих шагов нужна, чтоб была возможность просмотреть промежный итог.
Переходим к выгрузке данных из Google Analytics. Ранее мы теснее берегли токен. Сейчас мы его загружаем и проверяем валидность.
Дальше выстраиваем запрос к API GA для выгрузки органических сессий из Яндекса. В строке 79 прописываем номер счетчика GA, откуда будем выгружать данные.
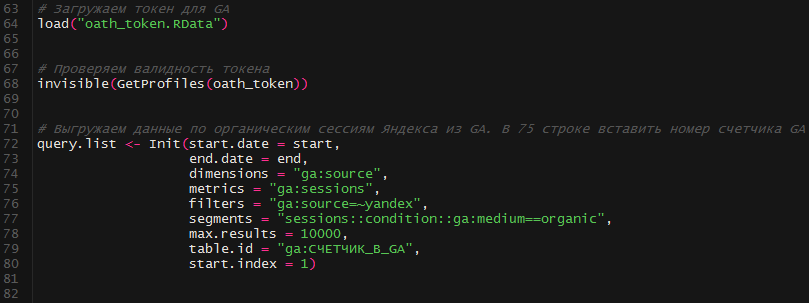
Делаем запрос к API и записываем данные в датафрейм. Настройка split_daywise = T дозволяет выгружать данные по дням, что исключает семплинг.

Суммируем сессии из Яндекса в переменную «y» и соединяем их с «x» в одном датафрейме.
Переходим к данным из Google Search Console.
Авторизуемся, при поддержки функции scr_auth формируем запрос к API. Для dimensionFilterExp необходимо каждую маску указывать как отдельный фильтр. К примеру: dimensionFilterExp =c( ‘query!~бренд’, ‘query!~brand’, ‘query!~брэнд’). Документацию по формированию таковых запросов можнож отыскать тут.
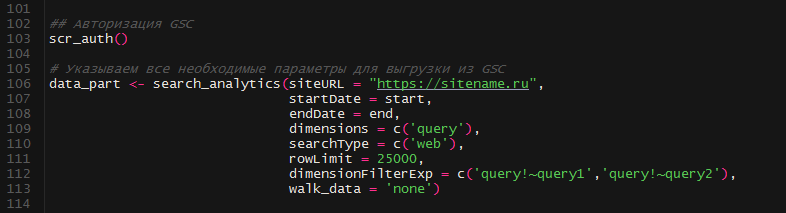
Суммируем небрендовые запросы Google и записываем их в переменную x_sum.

Подобно органическому трафику из Яндекс выгружаем сессии из Google. Их сумму записываем в переменную y_sum:
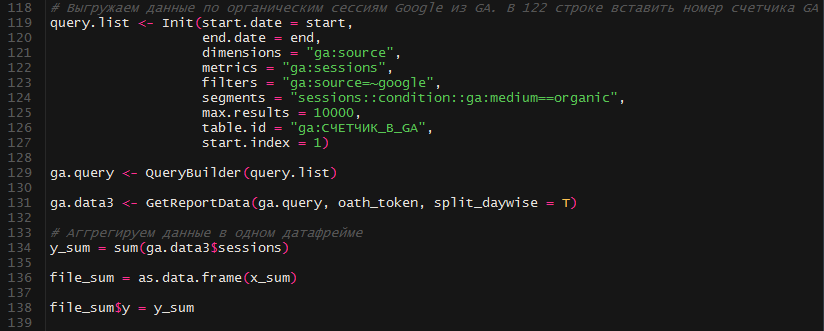
Еще несколько обычных событий, в каких мы соединяем все наши данные в одну табличку:

На выходе получаем последующее:

Можнож прямо в R посчитать долю в процентах, но мне необходимы данные в выгрузке конкретно в таком виде.
Дальше прописываем путь к файлу и формируем его заглавие. И, фактически, бережём файл в xlsx.

Главно держать в голове, что этот способ тоже не дает безусловно четкий итог. Данные в том же Google Search Console по кликам довольно ощутимо различаются от данных по трафику google / organic. Скрипт просто дозволяет довольно живо смонтировать данные из различных интерфейсов, обработать их и выдать итог.
Также стоит направить внимание на то, что данные в GSC обновляются с задержкой в 2–3 дня.
Комментариев: 0