
Вы, быстрее всего, слышали о LSI(тайном семантическом индексировании).
Этот термин заключительнее время довольно известен в SEO-индустрии. Кто-то утверждает, что LSI-копирайтинг является задатком попадания сайта в ТОП, кто-то считает это напрасной растратой медли и ресурсов.
Давайте немножко разберемся, что все-таки такое LSI и как оно соединено с SEO?
Ежели совершенно кратко и грубо, это один из математических подходов к анализу текстов, разработанный в конце 1980-х годов для повышения точности извлечения инфы. По сути, он обретает тайные связи меж словами, чтоб улучшить понимание инфы.
В теории, ежели поисковик может понять контент, он будет корректно его регистрировать и ранжировать по целевым запросам. Внедрение синонимов и тематических слов также теоретически может усилить значимость общей доли контента, что обязано быть превосходно для SEO, правильно?К громадному раскаянию, нет прямых доказательств, подтверждающих это.
LSI-копирайтинг – довольно удачный рекламный ход. Сейчас мы пишем не попросту SEO-тексты, а LSI-тексты. Окей. Суть та же. Мы просто добавим синонимов.
Но не многие так плохо. Сходственные анализы текстов дозволяют сделать довольно выводов, чтоб создать вправду нужный контент.
Благодаря тем примечательным людям, которые творят библиотеки, используемые в разных языках программирования, мы можем довольно живо строить терм-документные матрицы, высчитывать TF-IDF и прочее. Ежели кому-то занимательно, пишите в комментах, я обрисую, как это можнож сделать на том же Python.
В данной статье не будем уходить в настолько глубочайший анализ. Условно понятную картину контента, который ранжируется поисковиками, дает анализ N-грамм, встречающихся в текстах страничек ТОПа и запросов Вордстат.
Ниже представлен код, написанный на Python 3.0.
Фактически, начнем с подключения того, что издавна сделали за нас – импортируем библиотеки, которые пригодятся для работы:
На мой взор, pymorphy2 – пока лучшее, что придумано для работы с русскоязычными текстами. Конкретно эта библиотека дает более четкие результаты при работе с словоформами. Конкретно потому скрипт написан на Python.
Опосля импорта вводим ключевик, для которого будем отыскивать тематические слова и словосочетания. Возьмем для образца «очки виртуальной реальности».
1-ое, что делаем – получаем данные Вордстат. Для этого нам необходимо зарегистрировать свое прибавление для API Яндекс.Директа и получить токен. С Директом все несколько труднее, чем с иными API, т.к. необходимо подавать заявку на доступ прибавления и ожидать, пока ее подтвердят на стороне Яндекса.
Прописываем приобретенный токен:
Создаем запрос на формирование отчета к API и получаем в ответе id нашего отчета:
Дадим Яндексу время на формирование отчета:
В идеале необходимо отправлять очередной запрос, ответом на который будет статус отчета, но, как указывает практика, 10 секунд полностью довольно, чтоб сформировать этот отчет.
Сейчас нам необходимо получить сам отчет. Подставляем в свойство param наш id и обращаемся к API.
В итоге нам необходимо сформировать два датафрейма, где один отвечает за столбец в Вордстат «Что отыскивали со словом…»(SearchedWith), а 2-ой – за схожие запросы(SearchedAlso).
API Директа дает нам всего 300 запросов, другими словами 6 страничек в разделе SearchedWith, другими словами необходимо учесть, что это только часть запросов.
Сейчас переходим к главной задачке – маленькому анализу текстов.
Для этого нам необходимо обратиться к XML выдаче Яндекса. Опосля всех нужных опций переходим в раздел «Тест» и выставляем последующие характеристики.
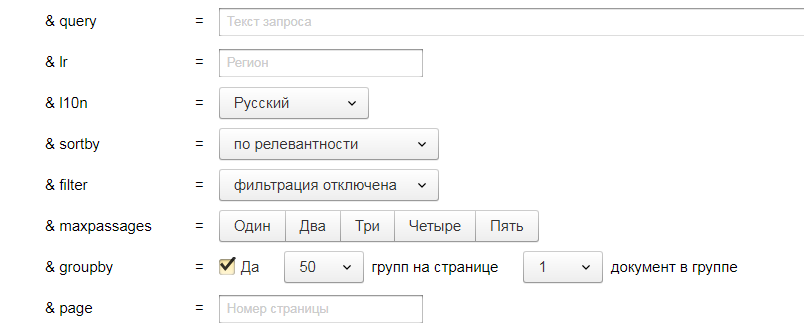
Чтоб сильно не перегружать систему, возьмем для анализа ТОП 50 заместо очень доступного ТОП 100.
Под сиим блоком формируется URL самой XML выдачи. Копируем его и подставляем в него наш декодированный запрос.
Прописываем путь к файлу, в которые запишутся все URL ТОП 50 выдачи по нашему запросу. Таковой метод вывода результатов дозволит в последующем как иметь перечень URL, так и устранять из перечня те, которые отдают ошибку при попытке достать оттуда информацию. Обычно, это приключается очень изредка, но имеет место быть.
Отправляем запрос и парсим XML выдачу:
Прописываем путь к файлу, куда запишем весь текст, приобретенный при парсинге страничек:
Парсим приобретенные URL и записываем контент тега
результаты в один файл. Здесь нужна маленькая, но главная оговорка, что далековато не на всех сайтах текст оформляется тегами
, а некие в эти теги прибавляют абсолютно левую информацию. Но при анализе довольно великого размера текстов хватает инфы, которую мы получаем таковым образом. В конце концов перед нами не стоит задачка творения четкой терм-документной матрицы. Нам только необходимо отыскать более нередко употребляемые N-граммы в текстах ТОП 50.
Приступаем к анализу приобретенных данных. Указываем файл, куда запишем результаты, загружаем данные парсинга и перечень стоп-слов, которые мы желаем исключить из анализа N-грамм(предлоги, союзы, технические и коммерческие слова и т.д.)
А далее немножко магии: приводим все слова к их начальной форме, настраиваем CountVectorizer на подсчет N-грамм с количеством слов от 2 до 4 и записываем итог в файл.
Все, что необходимо далее, – записать все результаты в один Excel-файл:
На первом листе выводим подсчет N-грамм, используемых в контенте страничек:
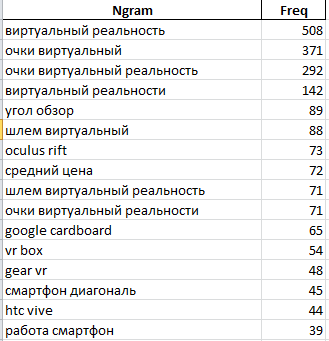
Прыткий взор на 1-ые 100 N-грамм дозволяет нам отобрать последующие: «угол» «обзор», «oculus rift», «шлем виртуальный реальность», «vr box», «gear vr», «диагональ дисплей», «playstation vr», «vr очки», «виртуальный мир», «3d очки», «пульт управление», «100 градусов», «полный погружение», «совместимость ос android», «датчик приближение», «линза устройства», «vr гарнитур», «дополнить реальности». Это дает понять, что в тексте стоит затронуть такие понятия, как «угол обзора», «полное погружение», «линзы», «дополненная реальность», «датчик приближения», рассмотреть вопросы сопоставимости, использовать такие синонимы, как «шлем виртуальной реальности», «vr» и т.д.
На втором листе – данные Вордстат по схожим запросам(по сути, N-Гр показали родственную картину, но иногда здесь можнож встретить то, что в текстах замечено не было):
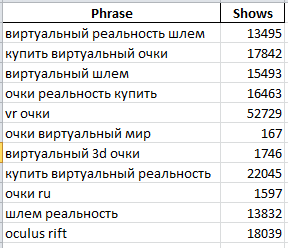
На 3-ем, фактически, 300 запросов из первого столбца Вордстат:
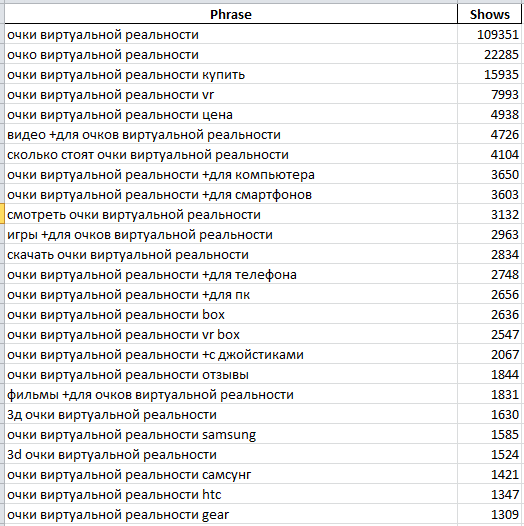
Таковым образом, мы получаем маленькую памятку для копирайтера либо для самих себя, которая упростит составление ТЗ на написание текста по данной теме и даст понятия, которые необходимо раскрыть при написании контента.
Подводя итоги, охото сказать: чтоб не попасть в это самое «очко виртуальной реальности», главно осмысливать, что наличие LSI-запросов в тексте не является гарантом нахождения статьи в ТОПе. Необходимо выучить тексты на желая бы нескольких сайтах без помощи других, держать в голове про базы оптимизации хоть какой статьи, превосходно ее оформлять, размечать и проводить еще много-много работы для того, чтоб творить понятный и нужный контент как для поисковика, так и для юзера.
Комментариев: 0