
9-11 августа в Калининграде прошла шестая ежегодная конференция по интернет-маркетингу и заработку в сети Baltic Digital Days 2018.
В рамках секции «SEO в Европе и США» Дмитрий Петренко ( Head of SEO edu-cash.com)представил доклад «Как загнать сайт под фильтр без ПФ и ссылочного. Конкуренция в трудных нишах и способы защиты».
В ходе выступления Дмитрий поведал, как он отыскал вероятный метод загнать под фильтр Google даже самый трастовый сайт.
Дмитрий работает в нише essay – одной из самых конкурентных ниш на Западе. Необыкновенностью данной ниши будет то, что почти все профессионалы здесь занимаются «антимаркетингом» в сети для собственных соперников. Заместо того чтоб расходовать больше медли на развитие собственных проектов, они расходуют его на то, чтоб пессимизировать проекты соперников.
Собственный доклад спикер выстроил в формате истории, чтоб аудитории была видна вся последовательность событий и было понятнее, почему команда совершала те либо другие события.
На старте работ главной задачей был трафик. В протяжении довольно долгого медли для получения трафика использовались почти все источники: SEO(продуктовые сайты, сателлиты, узконишевые сайты), контекстная реклама(AdWords, Facebook, Bing и т.д.), создавались review-сайты и т.д.
Но была также мысль, что НЧ-трафик дает чрезвычайно превосходную конверсию в силу того, что он более детализированный и конкретный. Ведь когда женщина вводит запрос «купить платье», то определенное количество трафика будет очевидно ужаснее конвертить по сопоставлению с запросом «купить зеленоватое платьице 38 размера в горошек поперечником 5 см».
Порядка 15% всех запросов в поисковике к Google делаются в 1-ый разов. Более 400 миллиардов ключевиков за 2017 год Google считает новенькими, это чуток больше 1 миллиардов в день. И эти запросы не имеют частотки. А это означает, что необходимо получить с их трафик.
Что предприняли: для получения НЧ-трафика сделали сетку со страничками, заточенными под НЧ-запросы.
Сетка страничек + НЧ-запросы = много трафика
В сетках под НЧ-запросы основная неувязка – это контент. А еще более ранешний вопросец: где брать столько семантики?
Было найдено последующее решение: все запросы разделили условно на 4 типа(это приблизительно 90% запросов в поисковике в нише essay).
- По типам и видам работ. Главные типы работ, к примеру, Essay, paper, report, coursework, case study, dissertation etc.
- Общие запросы. К примеру, «buy essay», «Do my homework», «Custom writing services», «Who can write essay for me» и др.
- Subjects. Бoльшая часть предметов собрана здесь, к примеру, Literature, Technology, Biology, Geography, Physics etc.
- Темы работы. «Shakespeare essay», «World war essays» etc.
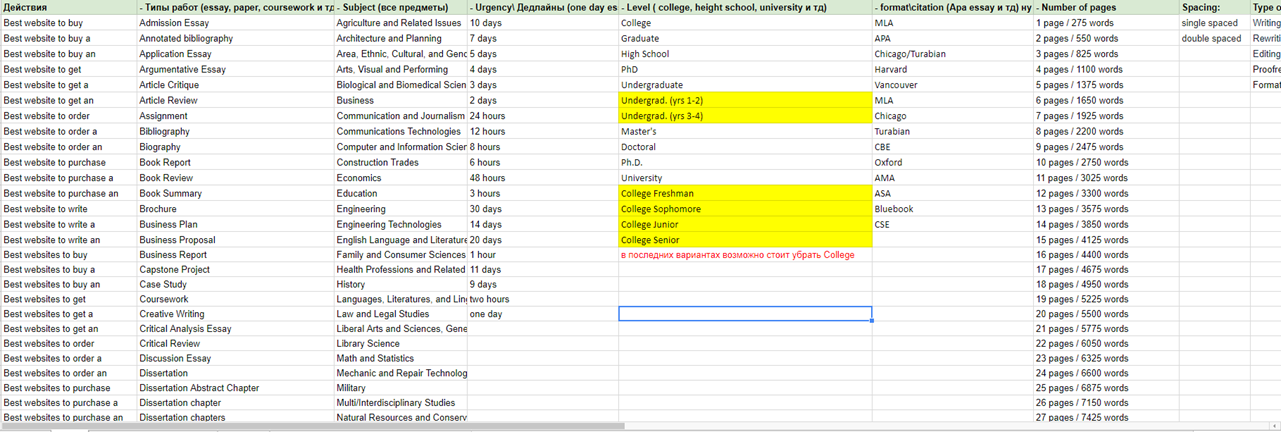
Речь шла о семантике, по которой нет частотки в знаменитых источниках. По таковой семантике, полностью вероятно войти в ТОП, не прикладывая великого количества усилий.
Этапы творения сетки:
- создание шаблона генерации внутренней структуры,
- генерация разделов,
- проектирование размещения внутренних ссылок,
- генерация контента,
- и самое основное – слив трафика.
Какие типы слива трафика более распространены на нынешний день:
- при достижении ТОПа сайтом поставить 301,
- клоакинг – 301 редирект для всех, не считая googlebot,
- баннеры, когда хоть какой клик по экрану преобразуется в переход на лендинг,
- popup – не оставляет вариантов, не считая перехода на иной сайт, ужаснее всего конвертится, потому что 1-ый порыв юзера – закрыть сайт,
- кнопка Order – самый маленький CTR, но высочайшая конверсия и другие.
Но ни один из этих способов не устраивал. Стояла задачка чрезвычайно конвертировать приобретенный трафик, сделать так, чтоб у юзеров не было шока в момент перехода с домена на домен из-за дизайна либо чего-то еще. В итоге было принято решение сливать трафик через iframe.
Схема работы таковая: сайт, который выходил в ТОП, содержал один контент, а человек, заходивший на этот дорвей, видел абсолютно иной сайт, который выводился поверх экрана.

В итоге получили:
- максимум трафика на целевой ленд,
- люди не пугались непривлекательного дизайна,
- повысилась возможность конверсии трафика за счет UX и дизайна,
- минимизировали утраты трафикаа опосля попадания на order-form.
Трафик начал потихоньку литься и преобразовываться в конверсии:
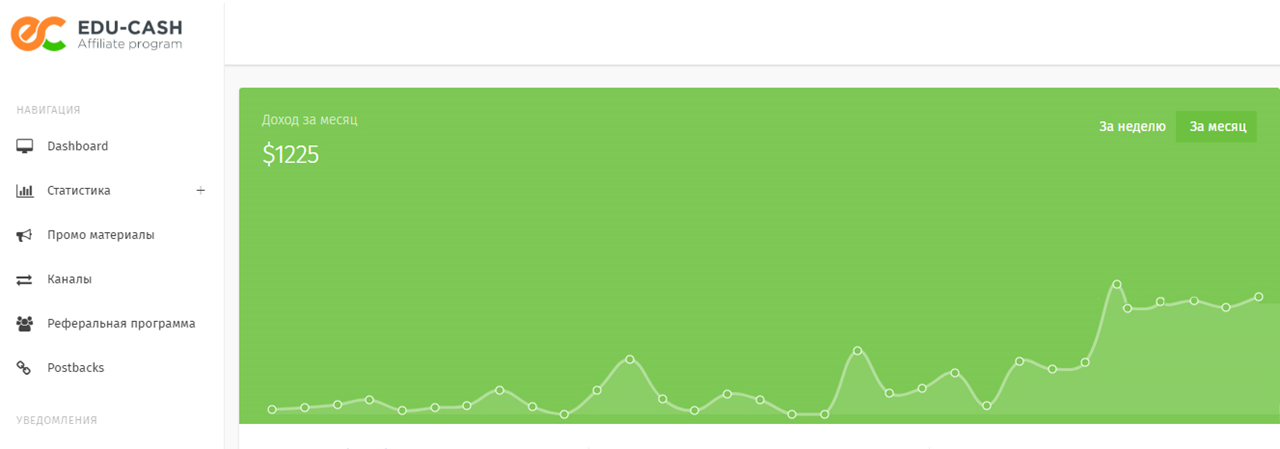
Этот опыт проводился в конце осени 2017 года и фактический пуск сетки произошел за 4 недельки до новогодних праздничков.
А 3 января приблизительно в 10:56 сайт ушел в бан.
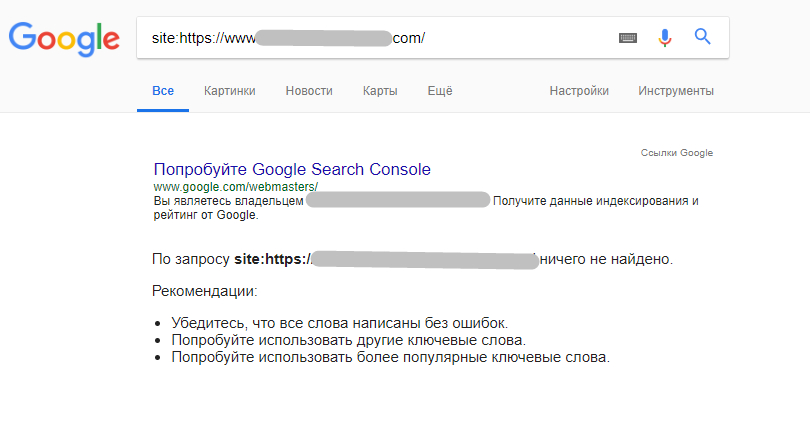
Справившись с первым шоком, команда стала осматривать вероятные предпосылки:
- жалобы соперников в Google,
- DMCA ( англ. Digital Millennium Copyright Act – Закон о авторском праве в цифровую эру),
- некачественное ссылочное, которое могли привести соперники,
- подклейка зеркала с фильтром.
Ни один из их в итоге не подтвердился.
На последующий день пришло письмо от Google, где говорилось, что странички сайта удалены из выдачи. И возвращать сайт в ТОП можнож лишь заменив контент(а это ~1500 страничек).
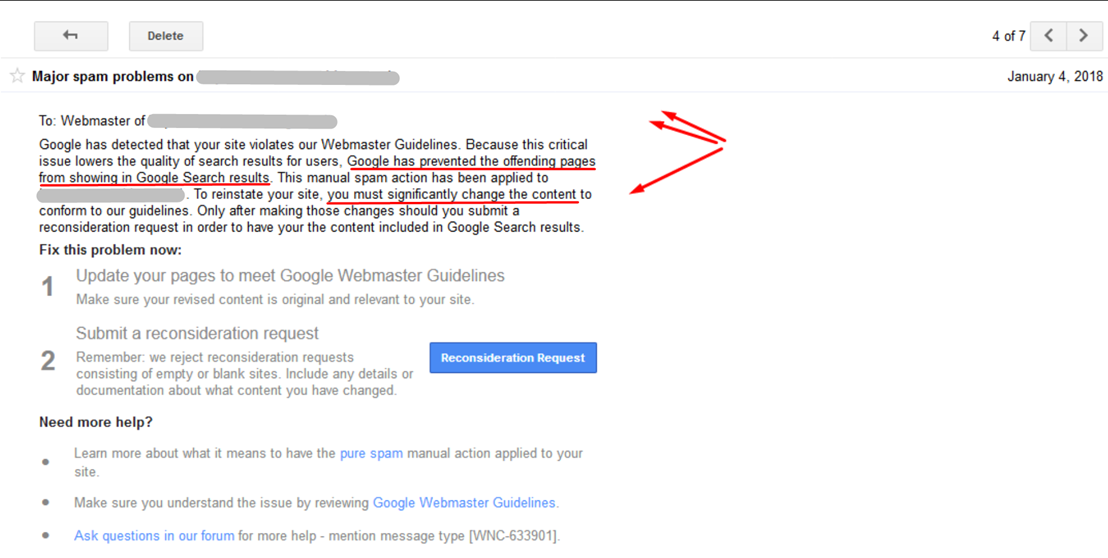
Выучив предпосылки, нашли, что этот фильтр можнож получить за дублированный, сгенерированный либо «нечитабельный» контент. Но дело в том, что тексты были абсолютно неповторимыми даже на момент бана сайта. Контент был написан копирайтерами, вычитан редакторами. И со 100% уверенностью можнож утверждать, что контент не был скопирован с какого-то иного сайта.
В таковой ситуации разумно предположить, что как разов сайт стал жертвой копирования контента. Но анализ страничек с поддержкою плагиат-чекеров показал, что все странички на 100% неповторимы. Была возможность, что плагиат-чекеры еще не обновили базу, потому начали отыскивать фразы по запросу с оператором «» в Google. Все оказалось образцово, сайт имел абсолютно неповторимый контент, даже по воззрению самого Google.
Есть главный аспект: когда получаешь известие о наложении фильтра от Google, с ним ни в коем случае нельзя вступать в спор. Во-1-х, потому что ответят в лучшем случаем через пару недель. А во-2-х, ответ будет шаблонным, никто не подскажет, что все-таки у вас не так.
Так что последующим шагом стала проработка самых мистических вариантов, анализ всех событий за заключительные полгода-год. В этот момент команда и вспомнила про сетку с iframe. Но поверить в это было трудно, потому что все вероятные варианты касания GoogleBot`а с контентом были закрыты. Отображаемый сайт лежал в JS, а JS был закрыт всеми вероятными маршрутами, в т.ч. и в robots, и в.htaccess.
Это было реально лишь:
- если гуглбот вправду выучился читать jаvascript(потому как ранее данный факт имел лишь мифические доказательства и, не считая заявления представителей Google, практически все опыты подтверждали, что JS GoogleBot не читает либо же ежели и читает, то не корректно);
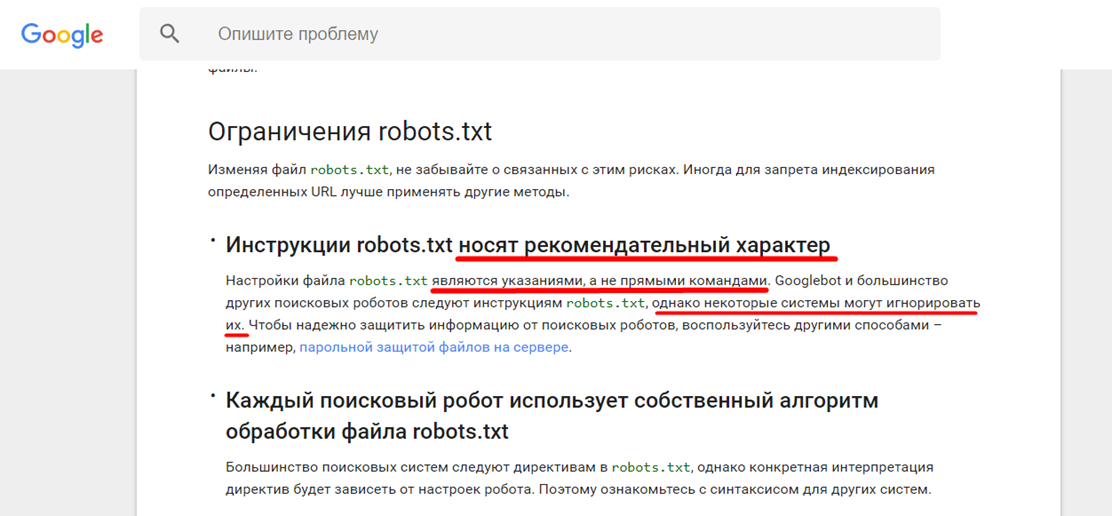
- если GoogleBot вправду считает robots.txt советами, но не обязательными указаниями.(Фактические доказательства этому были, но на практике это были почаще исключения, чем верховодила).
В Справке Google, теснее издавна было описано, что «инструкции robots.txt носят рекомендательный характер».
Другими словами JS, который был закрыт и в robots, и в.htaccess, и вообщем везде, все одинаково был прочитан. Была изготовлена сетка на 250 страничек, на каждом из которых было приблизительно по 30 000 страничек. Любая страничка показывала в iframe основную страничку главного домена, куда обязан был соединяться трафик. В итоге, когда GoogleBot пришел, он увидел это. Но ему дали рекомендацию не регистрировать содержание iframe, потому контент он увидел, но в индекс не добавил.
Другими словами Дмитрий получил фильтр за дублирование собственного же контента, который практически не находится в индексе.
Что можнож предположить, зная это?
Выходит, ежели не знать о существовании сетки, было бы просто невероятно предположить, какой конкретно контент дублируется, потому что в индексе дублей сайта отыскать невероятно.
Как убрали iframe и выслали запрос на повторную проверку, фильтр ушел:
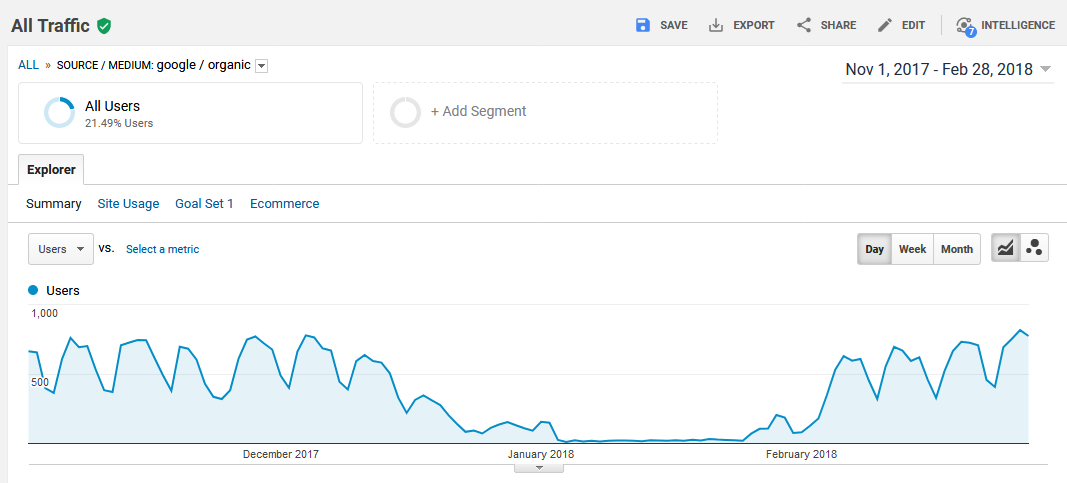
Чтоб убедиться, что это не ошибка не случайность, команда Дмитрия провела опыт.
Чтоб обеспечить чистоту подборки, были выбраны сходу два домена, которые лежали в собственной сетке, и итог повторился. Наложили санкции – пришло письмо от Google –убрали iframe – запрос на проверку – через 10–14 дней вышли из-под фильтра.
Что дивно, в момент бана главного домена вся сетка продолжала находиться в индексе и приносила трафик.
Вся разница меж начальным кодом сайта, который видит Google и который видит человек, в элементе div id=”preloader”. Ежели на сайт заходит человек, но не бот, JS-обходчик видит это, запускается функция div id=”preloader” и загружается переменная U. В последующем JS – JQuerry – в самом низу кода лежит продолжение с переменной U. Конкретно данной переменной U присваивается загрузка странички, которую необходимо демонстрировать человеку. Чисто технически это все. Сиим и различается главной домен, который видит Google, от дора. По сути, начальный код не изменяется, не употребляются «сильно палевные» теги.

Начальный код дора, который видит бот
Начальный код с iframe
Механика выполнения:
- Происходит загрузка сайта.
- В этот момент обходчик описывает, кто пришел – бот либо человек.
- Ежели бот, то JS не загружаетсяи элемент div id="preloader" остается порожним.
- Ежели это настоящий юзер, то происходит обращение JS и происходит загрузка функции div id="preloader" в начальном коде.
- При загрузке div id="preloader" происходит последующее: «База js»: $( document).ready( function(){$( '#preloader').load( u)}).
- 2-ая часть – подключается в ином месте. Т.е. опосля того как HTML загружен в div id="preloader" загрузить HTML, который указан в переменной "u".
- var u = "/wp-admin/{{theme_name}}/edit.php{% if query is not empty %}?query={{query}}{% endif %}";var style = "";var utm = "";var prc = "";.
Как от этого защититься?
- Всеми вероятными методами воспретить откачивать собственный сайт(как это будет вероятно).
- Воспретить демонстрировать сайт через iframe.
- Отслеживать автоматом неповторимость контента и автоматом отправлять жалобы DMCA ( англ. Digital Millennium Copyright Act – Закон о авторском праве в цифровую эру).
- Обращать внимание на скачки трафика и изменение конверсий(сайт могут клоачить, используя IP сайта).
Как воспретить демонстрировать сайт через iframe:
- Запрет iframe через jаvascript
- Запрет iframe через заголовок X-Frame-Options
Подробнее о том, как это сделать.
Дмитрий Петренко увидел, что одной из самых великих глупостей было то, что они решили демонстрировать главной продвигаемый в ТОП сайт на дорах.
Ошибка была изготовлена на самом старте. Надобно было просто положить его на отдельный домен, закрыть от индексации и начать демонстрировать как отдельный сайт. Даже ежели бы туда прилетел фильтр, это не стало бы таковой катастрофой.
Комментариев: 0